There is a certain excitement that comes with a client asking for real-time data processing. Everything in real-time. No batch jobs. No overnight waits. Just live, streaming data flowing from the source all the way to the gold layer. It sounds like the future — and in many ways, it is.
But the future, as it turns out, comes with caveats.
When our client approached us to modernize their data platform on Databricks, they had one clear requirement: all processing must run in real-time, from the source databases all the way to the gold layer, using SQL only. No PySpark, no complex orchestration scripts—just clean, readable SQL pipelines. We chose Databricks Delta Live Tables (DLT) as our framework — and for a while, it felt like the right call.
This blog is my honest account of where DLT delivered, where it struggled, and the hard lessons I learned about the boundary between what real-time can do and what it simply cannot — at least not yet.
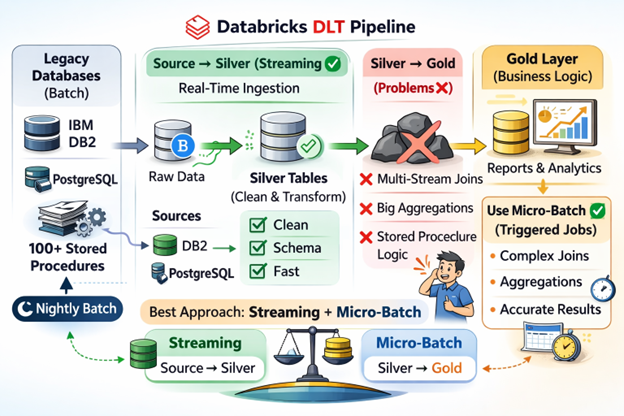
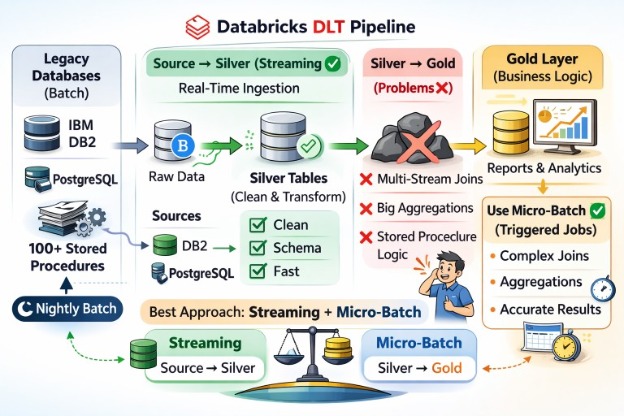
The Project Context: A Legacy World Entering Real-Time
To understand the challenges, it is essential to understand what we were working with. The client had a well-established, mature data pipeline built on two enterprise databases — IBM DB2 and PostgreSQL. Their transformation logic lived inside more than 100 stored procedures, accumulated over years of business growth.
These stored procedures were not simple lookups or basic joins. They were complex, multi-layered transformations — heavy on aggregations, conditional logic, multi-table joins, and business rules that had evolved. The final output was stored in a gold layer, which served as the source of truth for reporting and analytics.
The existing pipeline ran every night as a batch job. It was reliable, predictable, and — importantly — it had been built with batch processing in mind. The stored procedures were designed around the assumption that all data was available at the time of execution.
Then came the Databricks migration, and with it, a mandate that changed everything: real-time streaming from source to gold, using SQL only through Databricks DLT.
Why We Chose Delta Live Tables (DLT)
Databricks Delta Live Tables is a framework that simplifies building reliable, scalable, and maintainable data pipelines. It offers several compelling features that align with the client’s requirements:
- SQL-first approach, allowing declarative pipeline definitions without needing PySpark expertise
- Native support for both batch and streaming data processing
- Built-in data quality expectations and lineage tracking
- Automatic infrastructure management and pipeline orchestration
- Seamless integration with the Databricks Lakehouse and Unity Catalog
For the source to silver migration — ingesting raw data from DB2 and PostgreSQL and landing it in a cleansed, typed silver layer — DLT was genuinely excellent. Streaming tables picked up changes from the source, transformations were clean and readable, and the pipeline ran with minimal issues.
The problem began when we tried to take that same streaming philosophy all the way to the gold layer — where the real business logic lives.
Where DLT Worked Well: Source to Silver
Let us give credit where it is due. From source to silver, DLT performed remarkably well. The basic pattern of picking up records from DB2 and PostgreSQL via streaming, applying schema enforcement, light cleansing, and type casting, worked without significant friction.
A typical silver table in our pipeline looked like this:
CREATE OR REFRESH STREAMING LIVE TABLE silver_policy_holder
COMMENT "Cleansed and typed policy holder records from DB2 source"
TBLPROPERTIES ("quality" = "silver")
AS
SELECT
TRIM(POLICY_ID) AS policy_id,
TRIM(HOLDER_NAME) AS holder_name,
CAST(DOB AS DATE) AS date_of_birth,
CAST(PREMIUM AS FLOAT) AS premium_amount,
FIRMA AS company_code
FROM STREAM(raw.db2_source.POLICY_HOLDER) This worked because the operations were simple: one stream in, light transformations, one table out. No joins between streams. No aggregations. No window functions requiring full dataset context. DLT was designed exactly for this, and it delivered.
Where It Broke: The Silver to Gold Challenge
When we moved from silver to gold, we were essentially trying to replicate what those 100+ stored procedures had been doing for years — in real-time streaming. That is where things started to fall apart.
The Multi-Stream Join Problem
Our gold layer tables typically require joining data from multiple silver tables simultaneously. For a product dimension table, for example, we needed to join seven different silver tables — each defined as a streaming source — to produce a single, enriched gold record.
This is the exact query from our production pipeline that caused the first major error:
CREATE OR REFRESH STREAMING LIVE TABLE dim_product
AS
WITH thsp_produkt AS (
SELECT ... FROM STREAM(dgli_silver.abs_historical.THSP_PRODUKT)
),
thsp_druckbez AS (
SELECT ... FROM STREAM(dgli_silver.abs_historical.THSP_DRUCKBEZ)
),
tkz2 AS (
SELECT ... FROM STREAM(dgli_silver.abs_historical.TKZ_2)
),
-- ... 4 more streaming CTEs ...
base AS (
SELECT ...
FROM thsp_produkt a
JOIN thsp_druckbez dr ON dr.HSPP_ID = a.HSPP_ID
JOIN tkz2 b ON TRIM(a.HSP_EIGEN) = TRIM(b.DOMWERT2)
JOIN tkz2 c ON TRIM(c.DOMNAME) = 'HAUPTSPARTENGRUPPE' ...
LEFT JOIN tdombezugdet d ON ...
LEFT JOIN sales s ON ...
LEFT JOIN tkz3 t ON ...
)

The error message we received made the root cause very clear:
“Spark Structured Streaming does not support joining more than two streaming DataFrames/Datasets at once.”
Spark’s streaming engine requires watermarks to track the timing of events across streams. When you join two streams, Spark can manage the state. But when you add a third, fourth, or fifth stream to the join, it loses the ability to reason about timing and state boundaries. The operation simply does not support that level of complexity in streaming mode.
In our case, trying to replicate a stored procedure that joined seven tables in batch mode was fundamentally incompatible with how Spark Structured Streaming works. The framework is not arbitrarily restrictive — it reflects genuine computational constraints around stateful stream processing.
Complex Aggregations in a Streaming World
Many of our stored procedures performed aggregations that required full dataset context — things like calculating totals across all records for a given period, computing running balances, or deriving summary metrics across an entire product portfolio.
In batch processing, this is straightforward. You have all the data. You aggregate. You write the result.
In streaming, aggregations carry a different meaning. Spark needs to know when a window of data is “complete” before it can produce a final result. This requires watermarking — a mechanism to declare how late data can arrive before it is considered too old to include.
Our stored procedures had no concept of watermarks. They aggregated whatever was in the database at midnight. Translating this to streaming required either:
- Accepting approximate or partial results (not acceptable for a gold layer serving business reports)
- Using tumbling or sliding windows with aggressive watermarks (which still did not match batch semantics)
- Falling back to batch for the aggregation step (which undermined the real-time mandate entirely)
The Core Insight: Real-Time Is a Spectrum, Not a Switch
After working through these challenges, the most important lesson I took away was this: real-time streaming and complex business transformations are not natural partners — at least not in their current forms.
This is not a criticism of Databricks or DLT. It is a recognition of a fundamental architectural truth. Streaming engines are optimized for high-throughput, low-latency processing of continuous, well-defined event streams. They excel when:
- Operations are stateless or have bounded state
- Joins involve at most two streams with clear watermarks
- Aggregations can be windowed with an acceptable approximation
- Transformations are row-level or operate within a bounded partition
- Data has reliable timestamps for watermarking
They struggle when:
- Multiple streams must be joined simultaneously
- Global aggregations require full dataset context
- Complex business rules were written for batch semantics
- Deduplication depends on global ordering across all records
- The source data lacks reliable event timestamps
What is Recommended Instead
Based on this experience, here is the architecture pattern I would advocate for a similar project going forward:
Use Streaming from Source to Silver — Fully
This is where DLT shines without reservation. Streaming ingestion from operational databases into a silver layer with light transformations, type casting, and cleansing is a perfect use case. The latency improvements are real, the pipeline is maintainable, and the SQL-only constraint is easy to satisfy here.
Use Triggered Pipelines for Silver to Gold
For the gold layer — where complex joins, aggregations, and business logic live — use DLT in triggered mode rather than continuous streaming. A triggered pipeline runs on a schedule (every 5 minutes, every 15 minutes, or hourly, depending on business needs) and processes data in micro-batches. This gives you the benefits of DLT’s framework — lineage, quality checks, unified metadata — while using batch semantics for complex transformations.
-- Example: Triggered gold table (not streaming)
CREATE OR REFRESH LIVE TABLE gold_dim_product
COMMENT "Product dimension refreshed every 15 minutes.s"
TBLPROPERTIES ("quality" = "gold", "pipelines.trigger.interval" = "15 minutes")
AS
SELECT ...
FROM LIVE.silver_thsp_produkt a
JOIN LIVE.silver_thsp_druckbez dr ON dr.HSPP_ID = a.HSPP_ID
-- All 7 joins work fine here because these are batch tables, not streams
WHERE rn = 1
Redesign Stored Procedure Logic Incrementally
Rather than a direct lift-and-shift of stored procedures into DLT SQL, take the time to re-evaluate each procedure. Many stored procedures accumulate technical debt and redundancy over the years. A migration is an opportunity to simplify — break complex procedures into smaller, composable DLT tables that are easier to test and maintain.
Add Proper Timestamps to Silver Tables
If real-time stream joins become necessary in the future, the foundation needs to be laid now. Ensure every silver table carries a reliable event timestamp (not just a processing timestamp) so that watermarks can be properly defined when stream-to-stream joins are attempted.
DLT Streaming vs. DLT Triggered: At a Glance
Capability | DLT Streaming (Continuous) | DLT Triggered (Micro-Batch) |
Multi-stream joins | Limited to 2 streams | Fully supported |
Complex aggregations | Requires watermarks + windows | Fully supported |
ROW_NUMBER() deduplication | Semantically unreliable | Works as expected |
Latency | Seconds | Minutes (configurable) |
Use case | Source to Silver (ingestion) | Silver to Gold (business logic) |
Stored procedure migration | Mostly incompatible | Natural fit |
Conclusion
Real-time data processing is a powerful capability, and Databricks DLT is a genuinely excellent framework for building reliable, maintainable pipelines. But like any technology, it has a domain where it excels and a domain where it struggles.
When a client asks for “everything in real-time,” the job of a good data engineer is not simply to execute that request — it is to understand what they actually need and architect a solution that delivers on the business requirement without fighting the tool’s constraints.
In most cases, what the business needs is not true second-by-second streaming to the gold layer. What they need is for data to be fresh enough to make good decisions — and for that gold layer to be correct, trustworthy, and fast to rebuild when something changes.
Real-time is right for ingestion. Triggered micro-batch is right for complex transformation. The art is knowing which layer needs which approach — and having the confidence to push back when a blanket mandate does not serve the architecture.
The lessons from this project shaped how I now approach any migration involving streaming requirements: start with streaming where it genuinely helps, and be honest where it does not. That honesty, more than any technical skill, is what makes a good data engineer.