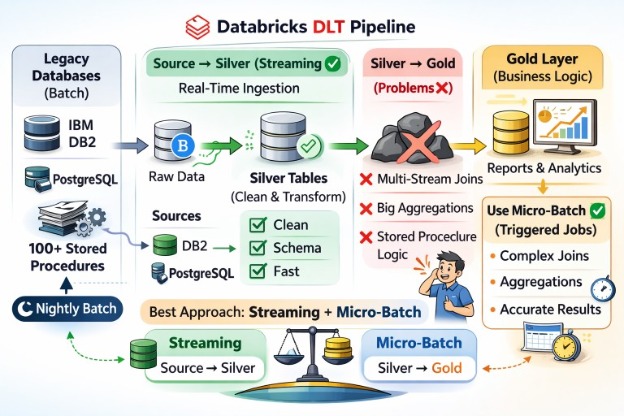
When Real-Time Meets Reality: Lessons from Using Databricks DLT in Production
There is a certain excitement that comes with a client asking for real-time data processing.
There is a certain excitement that comes with a client asking for real-time data processing.

This blog provides a comprehensive overview of integrating a MongoDB Atlas cluster with a custom

In 2026, businesses are mainly facing an unprecedented amount of data. The capability to harness

Databricks is transforming the modern data landscape by enabling enterprises to handle vast data volumes,

In data-driven enterprise environment, organizations are no longer asking whether they should modernize their data

Retail and consumer goods businesses know one truth: customers are no longer loyal to brands;