
In the ever-evolving world of data, ensuring high-quality and reliable datasets is more important than ever. Clean data fuels accurate analytics, drives better decision-making, and powers successful machine-learning models. However, poor data quality — caused by inconsistent formats, missing values, duplicate records, or outdated information — can lead to misleading insights and costly errors.
Databricks, a leading unified analytics platform built on Apache Spark, empowers organizations to process, analyze, and manage big data efficiently. It provides a collaborative environment for data engineers, data scientists, and analysts to work seamlessly across massive datasets.
To tackle data quality challenges, Databricks Labs DQX (Data Quality Expectations) offers a powerful framework to define, validate, and enforce data quality rules within Databricks. Whether you’re managing large-scale data pipelines or fine-tuning machine learning models, DQX helps ensure that your data is accurate, complete, and reliable — ready to fuel insights and innovation.
This blog walks you through the installation, data profiling, quality rule generation, and validation using DQX.
Setting Up DQX in Databricks:
To begin using DQX, install it in your Databricks environment via pip. Once installed, it seamlessly integrates with Databricks workflows, allowing users to implement quality checks with minimal effort.

Loading and Profiling Data:
The first step in applying data quality checks is loading the dataset into a Data Frame. Before defining rules, it’s crucial to profile the data. Data profiling provides key insights, including structure, data types, and missing values, helping users identify potential issues and optimize validation checks.


Sample data





Generating Data Quality Rules:
DQX enables the automatic generation of data quality rules based on profiling insights. These rules validate data integrity by enforcing constraints such as:
- Non-null values for critical fields.
- Range validation for numerical values.
- Predefined lists to check categorical data consistency.
Rules are typically stored in YAML or JSON files for easy management and automation.
Example YAML Rule for Data Validation:


Applying and Validating Data Quality Rules:
Once generated, these rules can be applied during data processing to ensure only clean, high-quality data moves forward.

This rule ensures that the column contains no missing values, preventing incomplete records from being processed.
Understanding Criticality Levels:
DQX allows users to define different criticality levels for validation:
Error: Data failing the check is quarantined.
Warning: Data proceeds with warnings but is not blocked.

Quarantined records
Customizing Data Quality Checks:
Beyond predefined rules, DQX supports custom validation using SQL expressions or Python functions. For example, users can enforce domain-specific constraints, such as verifying that all individuals in a dataset are at least 18 years old.
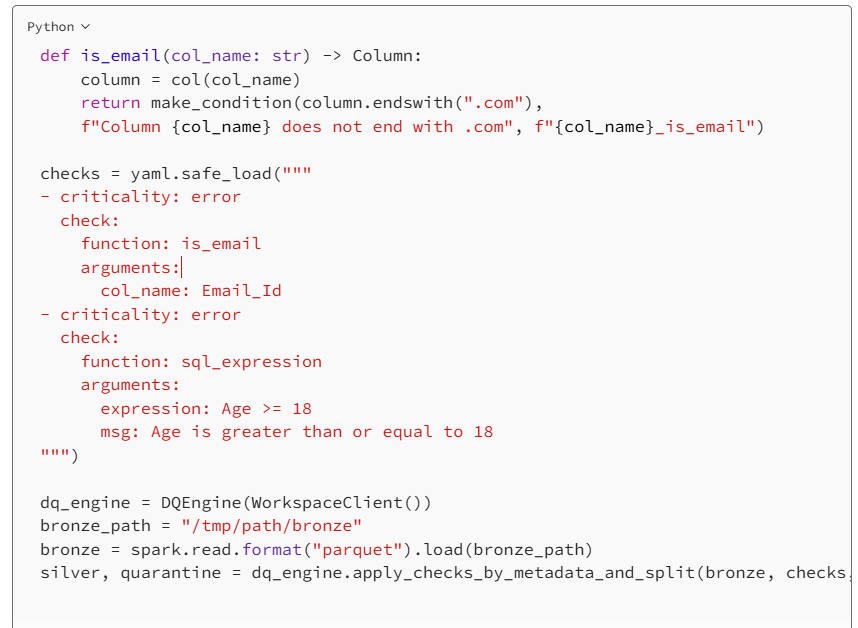
Defining Quality Rules as Code:
For users who prefer programmatic control, DQX enables the definition of validation rules as code, eliminating the need for external YAML or JSON configurations


Loading and Executing Data Quality Checks:
DQX supports multiple ways to load and execute checks:
- Loading checks from a workspace file in the installation folder – If DQX is installed in the workspace, checks can be loaded from the installation folder.
- Loading checks from a workspace file – Checks can also be loaded from any file within the Databricks workspace.
- Loading checks from a local file – Checks can be loaded from a file in the local file system.
- Loading checks from Azure Data Lake Storage (ADLS) – By mounting Databricks with ADLS, checks stored in a YAML file within ADLS can be accessed and loaded.
Conclusion:
Databricks Labs DQX empowers organizations with a scalable and automated framework for maintaining data integrity. Whether using predefined checks, YAML configurations, or custom functions, DQX ensures that data remains clean, reliable, and ready for advanced analytics and machine learning applications.
-Revathy S
Senior Data Engineer