People Decisions, Powered by Data: HRIQ + Databricks in Action

Hiring the right talent has always been one of the most critical priorities for organizations. Employees drive innovation, customer experiences, and long-term business performance. Yet despite its importance, the process of attracting, selecting, and onboarding employees has historically been riddled with inefficiencies. HR teams spend endless hours screening resumes, coordinating interviews, and onboarding new hires—only […]
Crystal Ball for Retail Business: DemandIQ + Databricks Redefining Forecasting

Retail has always been a business of margins, speed, and precision. Stock too little, and you lose customers to competitors. Stock too much, and you tie up working capital in slow-moving inventory while increasing markdown risks. Add in promotions, seasonality, supply disruptions, and rapidly shifting consumer behavior—and forecasting becomes less of a science and more […]
Handling CDC in Databricks: Custom MERGE vs. DLT APPLY CHANGES

Change data capture (CDC) is crucial for keeping data lakes synchronized with source systems. Databricks supports CDC through two main approaches: Custom MERGE operation (Spark SQL or PySpark) Delta Live Tables (DLT) APPLY CHANGES, a declarative CDC API This blog explores both methods, their trade-offs, and demonstrates best practices for production-grade pipelines in Databricks. Custom […]
Liquid Clustering in Databricks: The Future of Delta Table Optimization
Introduction — The Big Shift in Delta Optimization In the ever-evolving world of big data, performance tuning is no longer optional – it’s essential. As datasets grow exponentially, so does the complexity of keeping them optimized for querying. Databricks’ Liquid Clustering is a groundbreaking approach to data organization within Delta tables. Unlike traditional static partitioning, […]
Turning Notebooks into Dashboards with Databricks
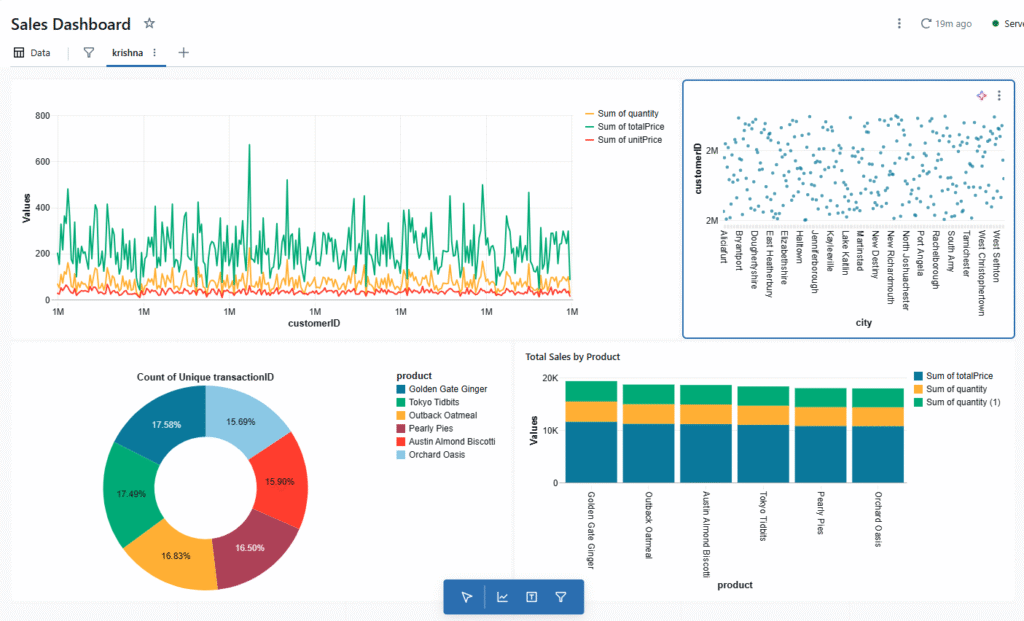
Why Databricks Notebook Dashboards Stand Out In the world of data-driven decision-making, dashboards are essential for turning raw numbers into actionable insights. While most dashboards help you visualize numbers, Databricks takes it a step further by making the process smooth, flexible, and tightly integrated with your working environment. Databricks notebook dashboards offer a unique blend […]
When to Use Databricks vs. PostgreSQL in Your Angular + NestJS Projects

Introduction Databricks is a powerful platform for huge data analytics, machine learning, and ETL pipelines. It’s optimized for processing massive datasets, now not coping with transactional workloads. However, many developers wonder: “Can I use Databricks at once in my Angular + NestJS app to keep and control statistics?” The answer: No — and here’s why. […]
Triggering Azure Data Factory (ADF) Pipelines from Databricks Notebooks
Overview In modern data workflows, it’s common to combine the orchestration capabilities of Azure Data Factory (ADF) with the powerful data processing of Databricks. This blog demonstrates how to trigger an ADF pipeline directly from a Databricks notebook using REST API and Python. We’ll cover: Required configurations and widgets Azure AD authentication Pipeline trigger logic […]
Delta Sharing: Let’s Share Seamlessly

Data became valuable the moment we started generating it at scale. As organizations began storing it by region — each with its own compliance rules, protocols, and security boundaries — the challenge shifted to: how do we share and consume data across regions securely, efficiently, and with minimal friction? Enter Delta Sharing: a modern, open, and cost-effective way to […]
Battle of the Data Titans: Databricks vs Microsoft Fabric Notebooks

In this blog, we break down the key differences between Microsoft Fabric and Databricks notebooks— comparing their pricing, features, and capabilities — to help you choose the right platform for your business needs. In today’s world, data is the backbone of decision-making, innovation, and business growth. With the explosion of big data, companies need powerful […]
Data Migration 2025: What It Is & Why It’s Important?

Data serves as the essential support structure across all industries today. Organizations seeking to modernize systems require efficient data migration to improve operational efficiency through improved data access. Partnering with the best data migration services company could make this transformation seamless and more secure. As businesses continue to grow, what is a data migration? Simply […]