Understanding RELATED and RELATEDTABLE Functions in Power BI

Data modeling is a foundational skill in Power BI, and mastering DAX functions that operate across related tables is essential for creating powerful and efficient reports. Two of the most useful functions for working with relationships in Power BI are RELATED and RELATEDTABLE. In this blog, we will explore what these functions do, when to […]
Event Stream vs Apache Kafka: Choosing the Right Engine for Real-Time Data

Introduction In today’s digital world, data is moving at the speed of thought. Imagine a fleet of 100 vehicles, each equipped with 200 sensors, continuously generating millions of events per second. This isn’t fiction — it’s happening in industries like logistics, automotive, and smart cities. If you delay this data by even 30 seconds, the […]
Liquid Clustering in Databricks: The Future of Delta Table Optimization
Introduction — The Big Shift in Delta Optimization In the ever-evolving world of big data, performance tuning is no longer optional – it’s essential. As datasets grow exponentially, so does the complexity of keeping them optimized for querying. Databricks’ Liquid Clustering is a groundbreaking approach to data organization within Delta tables. Unlike traditional static partitioning, […]
Apache Spark 4.0’s Variant Data Types: The Game-Changer for Semi-Structured Data

As enterprises increasingly rely on semi-structured data—like JSON from user logs, APIs, and IoT devices—data engineers face a constant battle between flexibility and performance. Traditional methods require complex schema management or inefficient parsing logic, making it hard to scale. Variant was introduced to address these limitations by allowing complex, evolving JSON or map-like structures to […]
Turning Notebooks into Dashboards with Databricks
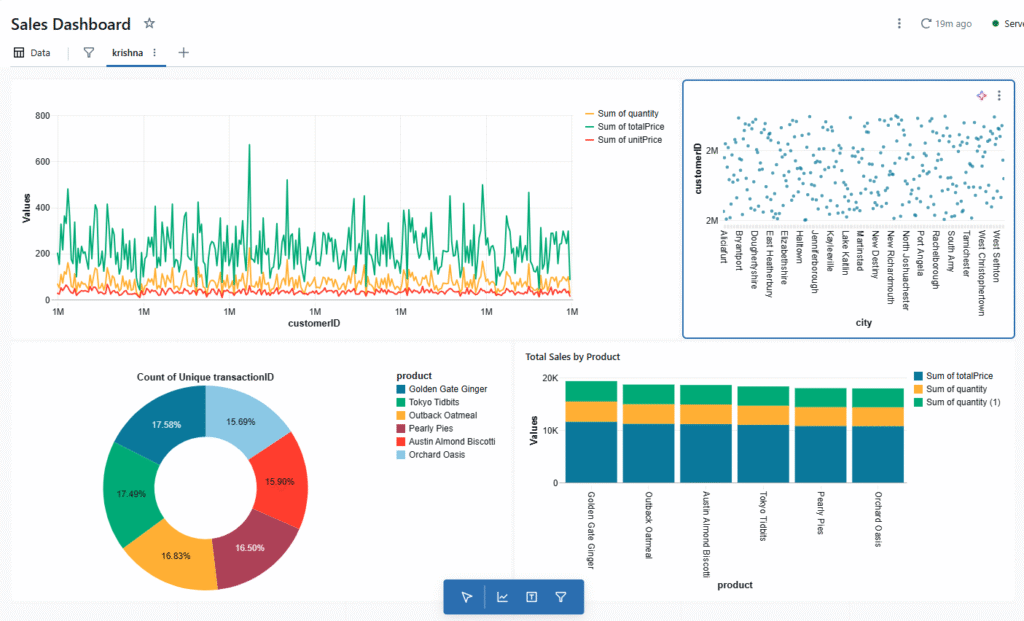
Why Databricks Notebook Dashboards Stand Out In the world of data-driven decision-making, dashboards are essential for turning raw numbers into actionable insights. While most dashboards help you visualize numbers, Databricks takes it a step further by making the process smooth, flexible, and tightly integrated with your working environment. Databricks notebook dashboards offer a unique blend […]
Ensuring Data Quality in PySpark: A Hands-On Guide to Deduplication Methods

Identifying and removing duplicate records is essential for maintaining data accuracy in large-scale datasets. This guide demonstrates how to leverage PySpark’s built-in functions to efficiently clean your data and ensure consistency across your pipeline. Predominant methods to remove duplicates from a dataframe in PySpark are: distinct () function dropDuplicates() function Using the Window function Using […]
Bulk API : An inevitable gamechanger

Essence: As businesses grow and handle ever-larger datasets, the demand for efficient data synchronization and management tools becomes increasingly essential. “Salesforce offers a robust ecosystem with a variety of APIs that facilitate seamless integration with external systems and enhance overall process efficiency.” It has become essential for the firm to deal with larger data sets […]
Triggering Azure Data Factory (ADF) Pipelines from Databricks Notebooks
Overview In modern data workflows, it’s common to combine the orchestration capabilities of Azure Data Factory (ADF) with the powerful data processing of Databricks. This blog demonstrates how to trigger an ADF pipeline directly from a Databricks notebook using REST API and Python. We’ll cover: Required configurations and widgets Azure AD authentication Pipeline trigger logic […]
Unleashing the Power of Explode in PySpark: A Comprehensive Guide

Efficiently transforming nested data into individual rows form helps ensure accurate processing and analysis in PySpark. This guide shows you how to harness explode to streamline your data preparation process. Modern data pipelines increasingly deal with nested, semi-structured data — like JSON arrays, structs, or lists of values inside a single column.This is especially common […]
Sync planner data to power bi using Power Automate.

Introduction: In today’s data-driven project environments, tracking work progress visually and in real time is no longer a luxury—it’s a necessity. Microsoft Planner serves as a great tool for managing team tasks and priorities, but when it comes to analytics, it hits a wall: there’s no native connector to Power BI. That’s where Power Automate […]