Data Migration 2025: What It Is & Why It’s Important?

Data serves as the essential support structure across all industries today. Organizations seeking to modernize systems require efficient data migration to improve operational efficiency through improved data access. Partnering with the best data migration services company could make this transformation seamless and more secure. As businesses continue to grow, what is a data migration? Simply […]
A Secure & Scalable Oracle Connection Strategy in Databricks Using OJDBC and Azure Key Vault

Difference between Data Science and Machine Learning [2025]

Knowing the difference between data science and machine learning is important for businesses and professionals. This knowledge helps them stay ahead in the AI-driven world. Data science focuses on extracting meaningful insights from structured and unstructured data. Machine learning enables systems to learn from data and make predictions using algorithms without explicit programming. Data science […]
Delta Lake Speed-Up: Z-Order on Single vs. Multiple Columns

Introduction As organizations ingest massive volumes of data into Delta Lake, query performance becomes critical, especially for dashboards, ad-hoc analysis, and downstream ETL jobs. One powerful technique to reduce query latency and improve data skipping is Z-Order Optimization. In this article, let’s cover: What Z-Ordering is How to apply it to single vs. multiple columns […]
From Big Data to Big Insights: Paginated Reports Made Easy

Introduction to Paginated Reports: Paginated reports are designed to be printed or shared. They are called paginated because they are formatted to fit well on a page. They display all the data in a table, even if the table spans multiple pages. You can control their report page layout exactly. Power BI Report Builder is […]
Data Visualization 2025: What It Is & Why It’s Important

Data visualization enables complex information to become graphical representations such as infographics, maps, graphs and charts amid the global exponential increase of data. This change allows business people and researchers to show data better. It helps improve communication, decision-making and understanding. Data visualization tools enable companies and data analysts to identify patterns and correlations hidden […]
Accelerating Change Data Capture with apply changes in Delta Live Tables (DLT): Simplifying SCD Type 1 & 2 Implementation
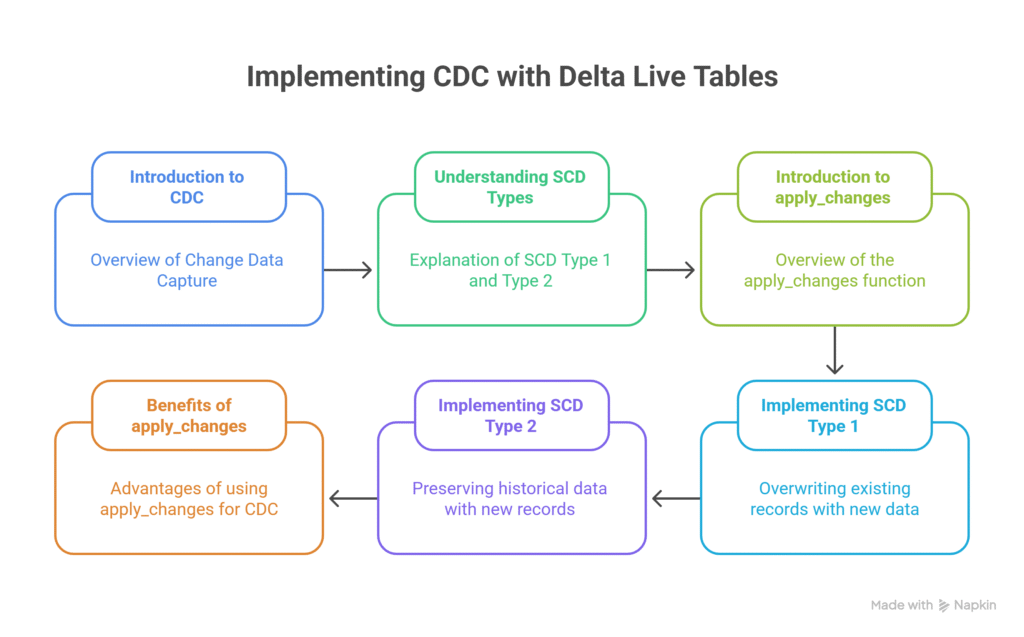
Introduction: Change Data Capture (CDC) is a crucial component of modern data engineering, enabling efficient tracking and processing of data changes from source systems. Traditionally, implementing CDC required complex and error-prone merge logic. With Delta Live Tables (DLT) in Databricks, CDC can now be implemented in a declarative, scalable, and reliable manner using the apply_changes […]
How Will Artificial Intelligence Affect Data Analysis in the Future

Introduction The role of data in modern decision-making has never been more critical. Organizations across all sectors are increasingly relying on data-driven insights to guide strategies, optimize operations, and foster innovation. However, the three V’s volume, variety, and velocity of data continue to grow exponentially, traditional data analysis methods are being pushed to their limits. […]
A Deep Dive into Persistent Storage in Flutter with SQLite & Shared Preferences

What are SQLite and Shared Preferences? SQLite is a lightweight, serverless database used for local data storage in mobile applications. It stores data in a single file on the device, making it ideal for offline-first app development. SQLite allows apps to read, write, and manage structured data efficiently without an internet connection. It is widely […]
Understanding Isolates in Dart and Flutter: A Guide to Efficient Concurrency

Introduction Dart is single-threaded by default, meaning heavy tasks can freeze your Flutter app’s UI. To prevent this, Dart offers Isolates—a way to run tasks in parallel without shared memory. This guide explains what isolates are, when to use them, and how to implement them effectively in Flutter. What are Isolates? Isolates are Dart’s solution […]