
Introduction:
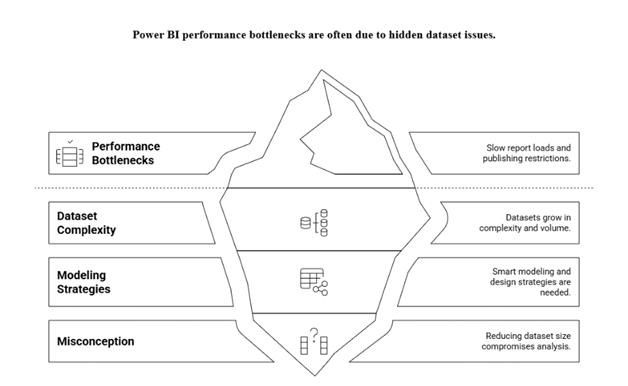
Power BI empowers organizations to turn data into actionable insights. However, as datasets grow in complexity and volume, performance bottlenecks, slow report loads, and publishing restrictions can arise.
One common misconception is that reducing dataset size means compromising on analysis or losing valuable data. But with smart modeling and design strategies, you can shrink your dataset size while still delivering rich, insightful reports.
Business Challenge:
Any organization building a Power BI report sourcing from millions of transactional records. The model started lagging as:
- Dataset exceeded size limits (especially with Power BI Pro)
- The report took 20+ seconds to load visuals
- User filters and slicers became unresponsive
- Publishing to the Power BI Service resulted in timeouts
They could not simply remove historical or granular data as business leaders relied on this data for trend analysis, forecasting, and segmentation.
Business Use Case:
I recently worked on a Retail Sales Report where the dataset was 1.5 GB in memory, with over 100M rows in the fact table and 20 dimension tables. The initial report load time was around 40 seconds, which was not ideal for a fast-paced business environment.
The business needed a flexible yet optimized reporting experience with:
- Daily transaction-level data for the last 3 months
- Monthly summarized data for the last 5 years
Proposed Solution:
Here is how I cut the dataset size without impacting reporting capabilities:
- Aggregation Tables (Summary Tables)
- Created a summarized table for sales by month.
- Used DAX and Power Query to summarize only older data.
- Retained granular detail only for the last 3 months.
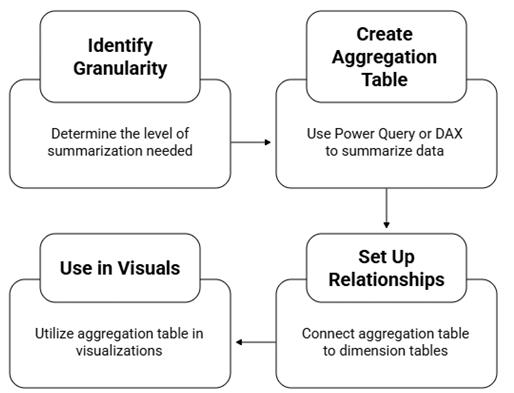
How to create Aggregation Tables in PBI:
Step 1: Identify Granularity of Aggregation:
Decide the level of summarization, such as:
- By Product and Month
- By Region and Category
Step 2: Create the Aggregation Table (in Power Query or DAX):
- Go to Transform Data.
- Reference your fact table.
- Use Group By to summarize:
Group by: Product, Month
Aggregations: Sum(Sales), Sum(Quantity), etc. - Rename the query to something like Sales_Agg.
Step 3: Set Up Relationships:
- Connect your aggregation table to the same dimension tables (Date, Product, etc.) used in your original fact table.
- Do not connect it to the main fact table.
Step 4: Use in Visuals:
- Use the same dimensions (Product, Date, etc.) in visuals.
Incremental Refresh
- Implemented incremental refresh on the fact table.
- Only new or changed data was refreshed daily.
- Applied RangeStart and RangeEnd parameters in Power Query.
Prerequisites for Incremental Refresh
- Your table must contain a date/time column.
- You’re using Power BI Pro (with Premium capacity) or Power BI Premium/Per User (PPU).
- The dataset must be published to the Power BI Service for incremental refresh to take effect.
- You must enable loading to the data model (can’t disable loading for the table).
How to apply Incremental Refresh in PBI:
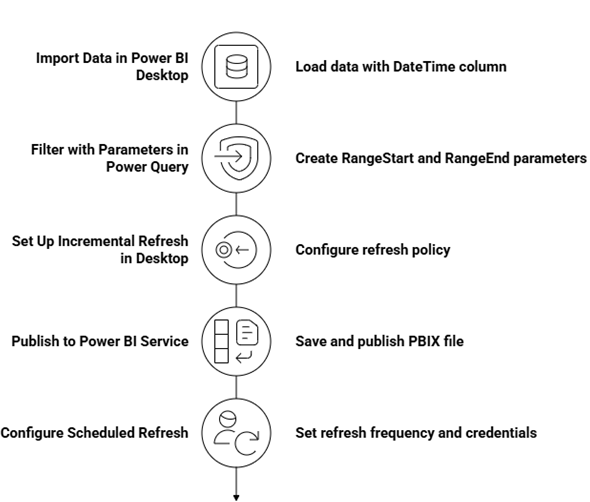
Step 1: Import Data in Power BI Desktop:
- Go to Home > Transform Data.
- Load the table that contains a Date or DateTime column (e.g., OrderDate).
Step 2: Filter with Parameters in Power Query
- In Power Query Editor, create two parameters:
- RangeStart (DateTime) → e.g., 2023-01-01
- RangeEnd (DateTime) → e.g., 2025-01-01
- Use these parameters to filter your table. This enables Power BI to partition data during refresh.
Step 3: Set Up Incremental Refresh in Desktop
- Go to Model View.
- Right-click on your table → Incremental refresh and real-time data.
- Set the refresh policy:
- Store rows from the past → e.g., 5 years
- Refresh rows in the last → e.g., 10 days (change detection window)
- Click Apply.
Step 4: Publish to Power BI Service:
- Save your PBIX file.
- Publish to a Premium workspace in the Power BI Service.
Step 5: Configure Scheduled Refresh:
- In Power BI Service, go to:
- Workspace > Dataset Settings > Scheduled refresh
- Enable and configure:
- Refresh frequency (daily, hourly, etc.)
- Credentials for the data source
Power BI will now only refresh new or updated partitions based on the OrderDate filter.
Column Reduction & Data Type Optimization
- Removed unnecessary columns (e.g., raw IDs, unused flags)
- Changed column types from Text to Categorical, and from Float to Decimal Number
Star Schema Restructure
- Flattened snowflake schema into a cleaner star schema.
- Combined lightly used dimension tables.
Filter-Driven Load (User Filtering)
Used parameterized queries in Power Query to only load relevant data.
