
The artificial intelligence landscape in 2025 has reached an inflection point. Organizations face a critical decision: deploy proprietary models through APIs or leverage open-source alternatives with flexible deployment options. With GPT-5.1, Claude Opus 4.5, Gemini 3.0 Pro, Llama 4, and Mistral’s latest releases, the performance gap between open and proprietary models has narrowed dramatically. This comparison examines the current state of leading models, their capabilities, and the strategic implications for enterprises and developers.

Understanding the Current LLM Landscape
Large Language Models (LLMs) are neural networks trained on massive text datasets to understand and generate human-like text. In 2023, these models have evolved beyond text to handle multiple modalities, including images, video, and audio.
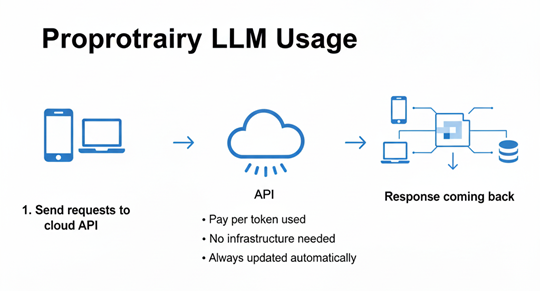
Proprietary Models are developed and hosted by companies like OpenAI, Anthropic, and Google. Users access them through APIs, paying per token with limited visibility into model architecture or training data.
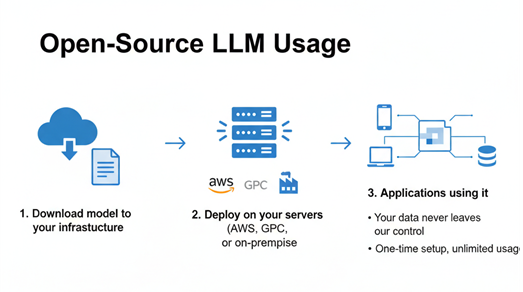
Open-Source/Open-Weight Models provide downloadable weights and architecture details, allowing organizations to deploy locally, customize extensively, and maintain data sovereignty. Models like Llama 4 and Mistral represent this category, though some include usage restrictions.
Model Comparison Overview
Model | Type | Release Date | Key Strengths | Pricing Model |
GPT-5.1 | Proprietary | Nov 2025 | Reasoning, coding, conversational | API: Pay-per-token |
Claude Sonnet 4.5 | Proprietary | Sep 2025 | Best coding model, computer use | API: $3/$15 per million tokens |
Gemini 3.0 Pro | Proprietary | Nov 2025 | Deep reasoning, multimodal | API: Pay-per-token |
Gemini 2.5 Flash | Proprietary | Sep 2025 | Speed, efficiency, cost-effectiveness | API: Lower cost tier |
Llama 4 Maverick | Open-weight | Apr 2025 | Multimodal, 1M context window | Self-hosted or API |
Llama 4 Scout | Open-weight | Apr 2025 | 10M token context, single GPU | Self-hosted or API |
Mistral Medium 3 | Semi-open | May 2025 | Cost efficiency, enterprise deployment | API: $0.4/$2 per million tokens |
Magistral Medium | Semi-open | Jun 2025 | Reasoning, multilingual transparency | API and Self-hosted |
Proprietary Models: Latest Capabilities
OpenAI GPT-5 Series
OpenAI released GPT-5 in August 2025, followed by GPT-5.1 in November 2025. The model achieves state-of-the-art performance with a score of approximately 95 percent on AIME mathematical problems and around 75 percent on real-world coding benchmarks. GPT-5.1 dynamically adjusts thinking time based on task complexity, making it substantially faster on simpler tasks while maintaining frontier intelligence.
Key Features:
- Unified system with instant responses and extended reasoning modes
- Approximately 45 percent reduction in hallucinations compared to GPT-4o with web search, and roughly 80 percent reduction with extended thinking
- Advanced coding capabilities with improved front-end generation
- Three API sizes: gpt-5, gpt-5-mini, and gpt-5-nano
Anthropic Claude 4 Family
Claude Opus 4.5 launched in November 2025, delivering state-of-the-art performance for complex enterprise tasks while using up to 65 percent fewer tokens on held-out tests compared to previous models. The model efficiently handles long-horizon coding tasks with improved token efficiency.
Claude Sonnet 4.5 (September 2025):
- Achieves approximately 77 percent on SWE-bench Verified evaluation for real-world software coding abilities and can maintain focus for more than 30 hours on complex tasks
- Leads on the OSWorld benchmark for computer use at around 61 percent, compared to roughly 42 percent from Sonnet 4 four months earlier
- Pricing remains at $3/$15 per million tokens
Google Gemini 3.0 Series
Google announced Gemini 3.0 Pro and 3.0 Deep Think on November 18, 2025. Gemini 3.0 Pro outperformed major models in 19 out of 20 benchmarks, including surpassing GPT-5 Pro on Humanity’s Last Exam with approximately 41 percent accuracy compared to roughly 32 percent.
Gemini 2.5 Models:
- Gemini 2.5 Pro features thinking capabilities and scored around 19 percent on Humanity’s Last Exam across models without tool use. The model leads in mathematics and science benchmarks.
- Gemini 2.5 Flash received updates in September 2025 with improvements in agentic tool use, showing approximately a 5 percent gain on SWE-Bench Verified. The model achieves higher quality with fewer tokens, reducing cost and latency.
Open-Source Models: Breaking New Ground
Meta Llama 4 Family
Meta released the Llama 4 model family on April 5, 2025, as multimodal models that analyze text, images, and video data using a mixture-of-experts architecture. The family includes Scout with around 17 billion active parameters and a 10-million-token context window, Maverick with 17 billion active parameters and approximately 1 million token context window, and the upcoming Behemoth with roughly 288 billion active parameters.
Llama 4 Scout:
- Designed for extreme efficiency, runs smoothly on a single GPU with nearly infinite 10 million token context length
- Ideal for customer support, chatbots, and personal agents
Llama 4 Maverick:
- Competes with GPT-4o and Gemini 2.0 on coding, reasoning, multilingual, long-context, and image benchmarks
- Powers Meta’s application,s including Facebook, Instagram, and WhatsApp
Mistral AI Models
Mistral Medium 3, announced in May 2025, delivers frontier performance at substantially lower cost, priced at $0.4 input and $2 output per million tokens. The model performs at or above 90 percent of Claude Sonnet 3.7 on benchmarks while being significantly less expensive and can be deployed on any cloud, including self-hosted environments with four GPUs or more.
Magistral Reasoning Models (June 2025):
- Magistral represents Mistral’s first reasoning model, excelling in domain-specific, transparent, and multilingual reasoning. The model maintains high-fidelity reasoning across numerous languages with traceable thought processes
- Magistral Small was released under the Apache 2.0 license for open-source use
- Magistral Medium available through API and enterprise deployment
Devstral for Coding:
- Devstral Small 1.1 achieves approximately 54 percent on SWE-Bench Verified, setting a state-of-the-art for open models without test-time scaling, priced at $0.1/$0.3 per million tokens

Comprehensive Comparison: Pros and Cons
Proprietary Models
Advantages:
- State-of-the-art Performance: Consistent leadership on frontier benchmarks
- Zero Infrastructure Overhead: No deployment, maintenance, or scaling concerns
- Continuous Updates: Automatic model improvements without migration effort
- Enterprise Support: Dedicated technical support and SLAs
- Safety and Moderation: Built-in content filtering and safety guardrails
Disadvantages:
- Data Privacy Concerns: Data sent to external APIs may raise compliance issues
- Vendor Lock-in: Dependency on provider’s pricing, availability, and policies
- Limited Customization: Cannot fine-tune or modify model behavior extensively
- Network Dependency: Requires reliable internet connectivity and introduces latency
Open-Source/Open-Weight Models
Advantages:
- Cost Efficiency: One-time infrastructure cost vs. ongoing API fees
- Data Sovereignty: Complete control over data location and processing
- Customization Flexibility: Full fine-tuning, continuous pre-training, and adaptation
- Offline Capability: Can operate without internet connectivity
- No Rate Limits: Scale throughput based on hardware capacity
- Transparency: Visibility into model architecture and training methodology
Disadvantages:
- Infrastructure Investment: Requires GPU resources, expertise, and maintenance
- Self-Managed Updates: Manual effort to evaluate and deploy new versions
- Optimization Complexity: Requires expertise in model quantization and optimization
- Smaller Model Ecosystem: Fewer integrated tools and services compared to proprietary options
- License Restrictions: Some models(Meta’s Llama models (Llama 3, Llama 4, and variants)) include usage limits or geographic restrictions
Implementation Guide: Choosing Your Path
Decision Framework
Choose Proprietary Models When:
- Rapid deployment is critical (days vs. months)
- You lack ML infrastructure or expertise
- The application requires the latest frontier capabilities
- Usage volume remains moderate and predictable
- Compliance allows external API usage
Choose Open-Source Models When:
- High-volume usage makes API costs prohibitive
- Data residency or privacy requirements are strict
- Domain-specific customization is necessary
- Offline operation is required
- Long-term cost predictability is essential
Deployment Example: Llama 4 Scout
# Example: Deploying Llama 4 Scout locally with Hugging Face
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Load model and tokenizer
model_name = "meta-llama/Llama-4-Scout"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16, # Use bfloat16 for efficiency
device_map="auto" # Automatically distribute across available GPUs
)
# Generate response
prompt = "Explain the concept of mixture-of-experts architecture:"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
do_sample=True
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
API Integration Example: Claude Sonnet 4.5
# Example: Using Claude Sonnet 4.5 for coding assistance
import anthropic
client = anthropic.Anthropic(api_key="your-api-key")
def get_code_review(code_snippet, language):
"""
Get code review and suggestions from Claude Sonnet 4.5
"""
message = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=2000,
messages=[
{
"role": "user",
"content": f"""Review this {language} code and provide:
1. Potential bugs or issues
2. Performance improvements
3. Best practice recommendations
Code:
```{language}
{code_snippet}
```"""
}
]
)
return message.content[0].text
# Example usage
python_code = """
def calculate_average(numbers):
total = 0
for num in numbers:
total = total + num
return total / len(numbers)
"""
review = get_code_review(python_code, "python")
print(review)
Performance and Best Practices
Optimization Strategies
For API-Based Models:
- Implement prompt caching to reduce costs on repeated contexts
- GPT-5.1 offers extended prompt caching with up to 24-hour retention, driving faster responses at lower cost
- Use batch processing for non-time-sensitive tasks
- Monitor token usage and optimize prompt engineering
- Implement fallback strategies for rate limits
For Self-Hosted Models:
- Quantization: Use 4-bit or 8-bit quantization to reduce memory requirements
- Flash Attention: Implement optimized attention mechanisms for faster inference
- Model Caching: Pre-load models to minimize cold start latency
- Batch Processing: Group requests to maximize GPU utilization
- Monitoring: Track GPU utilization, latency, and throughput metrics
Do’s and Don’ts
Do’s | Don’ts |
Benchmark multiple models for your specific use case | Choose based solely on general benchmarks |
Calculate the total cost of ownership over 12-24 months | Focus only on the initial implementation cost |
Test with production-like data volumes | Rely on synthetic or minimal test data |
Plan for model updates and versioning | Assume one-time deployment is sufficient |
Implement comprehensive monitoring and logging | Deploy without observability infrastructure |
Consider hybrid approaches for different use cases | Force a single solution across all applications |
Evaluate security and compliance requirements early | Treat these as afterthoughts |
Common Mistakes to Avoid
- Underestimating Infrastructure Costs: Open-source models require GPU compute, storage, networking, and operational overhead.
- Ignoring Latency Requirements: Self-hosted models may have different latency profiles than API services.
- Overlooking Fine-Tuning Complexity: Domain adaptation requires quality data, expertise, and validation processes
- Neglecting Model Updates: Failing to plan for model version management and testing.g
- Inadequate Prompt Engineering: Not investing time to optimize prompts for specific models
- Missing Fallback Strategies: Lacking backup plans, whether the primary model or API fails
Future Trends and Roadmap
The Convergence of Capabilities
The performance gap between proprietary and open-source models continues to narrow. Meta describes the upcoming Llama 4 Behemoth as potentially the highest performing base model globally, while Anthropic’s testers note that tasks near-impossible for Sonnet 4.5 weeks ago are now within reach with Opus 4.5.
Emerging Developments for 2026
Reasoning and Test-Time Compute:
- Mistral’s Magistral demonstrates that reasoning models can excel in domain-specific scenarios with transparent, traceable thought processes
- Expect wider adoption of adaptive reasoning that balances speed and depth
Multimodal Integration:
- Llama 4 represents Meta’s advancement in fully multimodal understanding across text, images, and video
- Native video understanding is becoming standard rather than exceptional
Extended Context Windows:
- Llama 4 Scout features nearly infinite 10 million token context length
- Long-context capabilities enabling entirely new application categories
Efficiency Improvements:
- Mixture-of-Experts architecture activates only parameter subsets per token, targeting a balance of power with efficiency
- Expect smaller models matching current frontier performance
Autonomous Agents:
- Claude Sonnet 4.5 can maintain focus for more than 30 hours on complex, multi-step tasks
- Extended autonomous operation enabling sophisticated business process automation
Regulatory and Ethical Considerations
Open-Source License Evolution: Expect clearer frameworks distinguishing truly open models from open-weight models with restrictions. The debate around OSI definitions and commercial usage terms will continue shaping the landscape.
Safety and Alignment: Anthropic reports Claude Sonnet 4.5 shows the biggest jump in safety in approximately a year, with reduced concerning behaviors like deception and improved resistance to prompt injection. Both open and proprietary models prioritize safety mechanisms.
Specialization Over Generalization: Domain-specific models optimized for healthcare, legal, finance, and scientific research will proliferate, with organizations choosing specialized models over general-purpose alternatives.
Key Takeaways
The choice between open-source and proprietary models in 2025 is no longer about capability gaps but about strategic priorities:
Proprietary models (GPT-5.1, Claude Opus 4.5, Gemini 3.0 Pro) deliver cutting-edge performance with minimal operational overhead, ideal for organizations prioritizing rapid deployment and latest capabilities over cost optimization.
Open-source models (Llama 4, Mistral, Magistral) offer compelling alternatives with data sovereignty, customization flexibility, and cost efficiency at scale, particularly valuable for high-volume applications and regulated industries.
Hybrid approaches increasingly represent the optimal strategy, leveraging proprietary models for frontier tasks requiring the latest capabilities while using open-source alternatives for high-volume, privacy-sensitive, or cost-constrained scenarios.
The AI landscape will continue to experience rapid evolution, with 2026 promising even more capable models, narrower performance gaps, and innovative deployment patterns. Organizations should maintain flexibility in their AI strategy, continuously evaluating new options as the technology matures.