Liquid Clustering in Databricks: The Future of Delta Table Optimization
Introduction — The Big Shift in Delta Optimization
In the ever-evolving world of big data, performance tuning is no longer optional – it’s essential. As datasets grow exponentially, so does the complexity of keeping them optimized for querying.
Databricks’ Liquid Clustering is a groundbreaking approach to data organization within Delta tables. Unlike traditional static partitioning, Liquid Clustering dynamically clusters data based on frequently queried columns, allowing for more balanced data distribution and faster query performance – even as data grows to massive scales. This innovation enables teams to manage large, evolving datasets with minimal manual intervention, ensuring optimal performance over time.
Limitations of Traditional Approaches
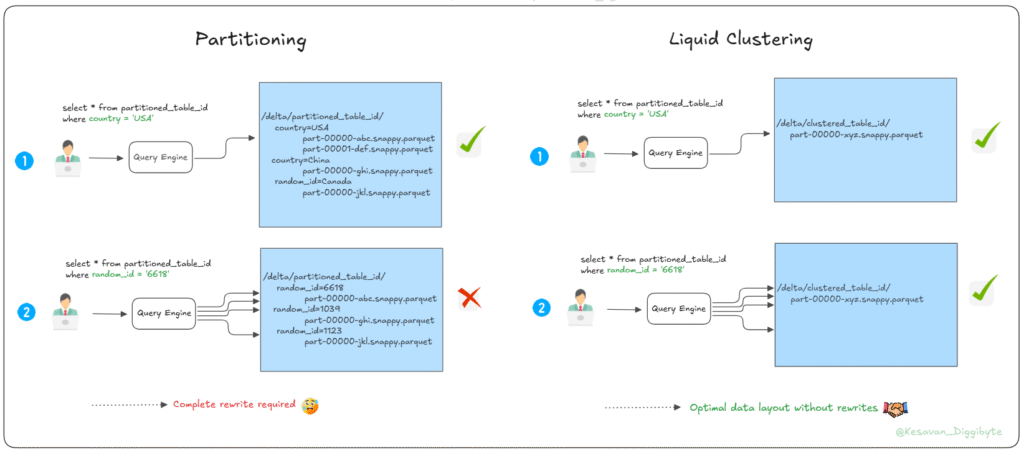
For years, static partitioning has been the go-to strategy for improving Delta table read performance. While partitioning is effective when the filtering column has low cardinality (few distinct values), it breaks down when:
The partition column has high cardinality (e.g., IDs, timestamps).
You need both streaming and batch optimization without manual intervention.
In our case, partitioning on a high-cardinality column caused small files to multiply and queries to slow down badly.
Liquid Clustering
Liquid Clustering changes the game by dynamically organizing data for optimal skipping at read time. Instead of physically storing each value in its own partition folder (like static partitioning), it clusters data intelligently inside files, keeping file sizes healthy and enabling efficient data skipping.
Think of it this way:
Partitioning = many small filing cabinets (good for few categories, bad for many).
Clustering = one big smart cabinet with labeled drawers that automatically rearrange themselves for faster access.
Hands-On Experiment
Internal Execution of Partitioning and Liquid Clustering
Static Partitioning: Creates one directory per unique value of random_id. With high cardinality, this leads to too many small partitions, resulting in inefficient queries.
Liquid Clustering: Organizes data into optimized clusters within files instead of separate folders, improving query performance and reducing storage overhead.
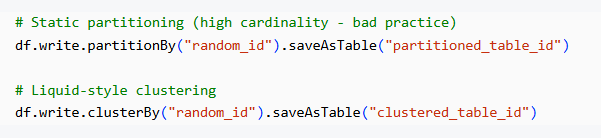
To demonstrate how partitioning and clustering differ, I created two tables in Databricks using the same high-cardinality column:
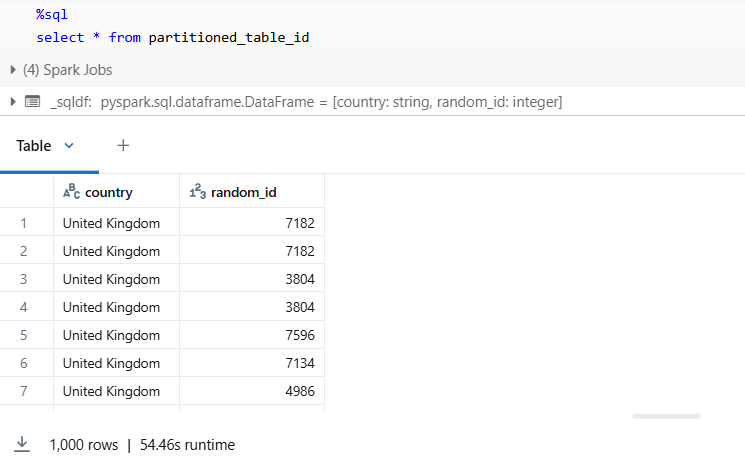
Table 1: partitioned_table_id — created with partitionBy
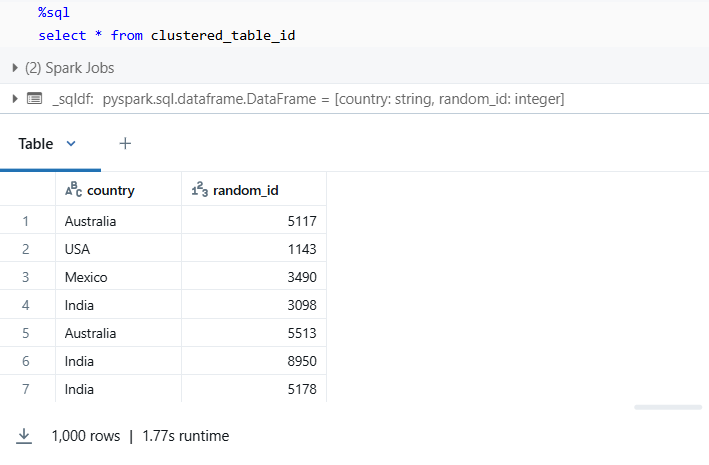
Table 2: clustered_table_id — created with clusterBy (Liquid Clustering style)
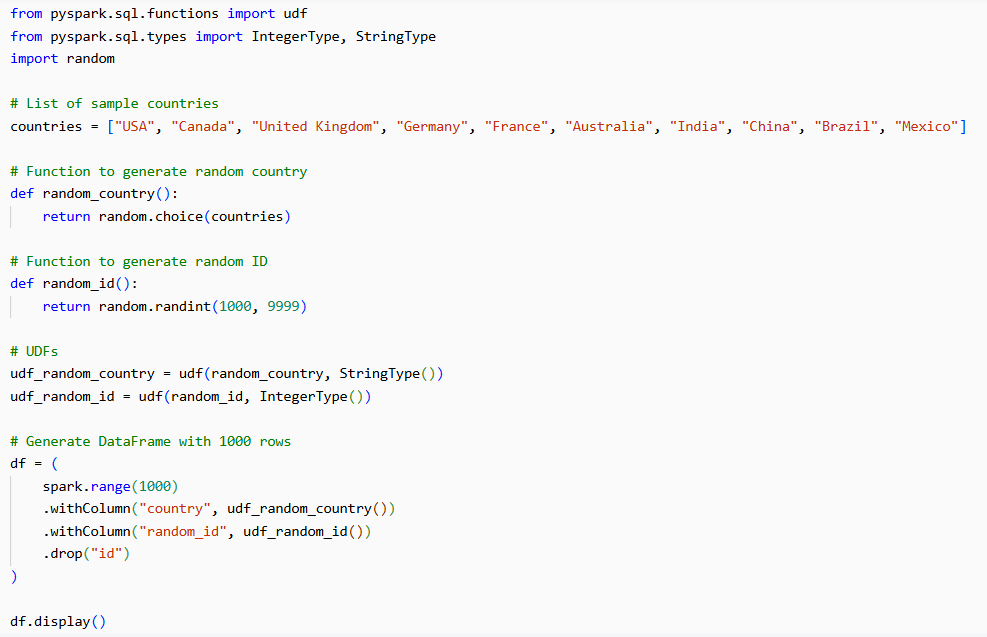
Step 1: Create Sample Data in PySpark
We start by generating 1,000 random records containing two columns:
country → Random country name
random_id → Random numeric ID (high cardinality)
Step 2: Writing Tables — Choosing Between Partitioning and Clustering
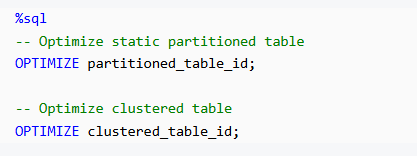
Step 3: Optimize Both Tables After writing, we run OPTIMIZE to compact small files into larger files for better performance:
Step 4: Performance Test
Measure the performance improvement, we ran a SELECT query on each of the tables.
Observation:
Static partitioning required 54.46s to retrieve all rows.
Liquid clustering completed the same query in 1.77s – 30x speed improvement on this small dataset.
Scaling Considerations:
In this, we used a small dataset of only 1,000 rows to illustrate the concept. In real-world production environments, where datasets often reach millions or even billions of rows, the performance gains from Liquid Clustering are far more pronounced — often translating to substantial reductions in query execution time and overall compute cost.