
Change data capture (CDC) is crucial for keeping data lakes synchronized with source systems. Databricks supports CDC through two main approaches:
- Custom MERGE operation (Spark SQL or PySpark)
- Delta Live Tables (DLT) APPLY CHANGES, a declarative CDC API
This blog explores both methods, their trade-offs, and demonstrates best practices for production-grade pipelines in Databricks.
Custom MERGE INTO: Flexibility with Complexity
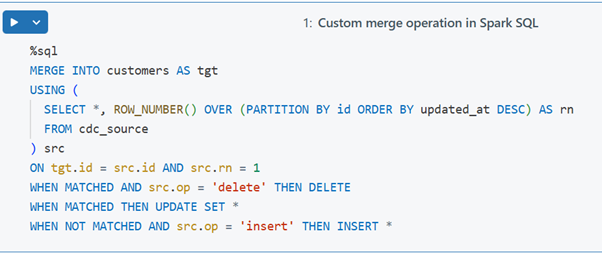
Traditional CDC via MERGE INTO requires manual orchestration:
- Deduplicate and order records
You must identify the most recent change per key using window functions (e.g., timestamps) and filter accordingly - Custom merge logic
Specify WHEN MATCHED and WHEN NOT MATCHED clauses to implement INSERT, UPDATE, and DELETE logic. - Manage out-of-order events
Without strict ordering logic, late-arriving records can lead to inconsistent updates - Operational overhead
You must optimize, partition, handle errors, and tune performance—all manually.
Example:
DLT APPLY CHANGES: Declarative CDC Simplified
Delta Live Tables (DLT) offers declarative CDC via APPLY CHANGES, designed for streaming and batch CDC workloads
Key Features:
- Automatic sequencing and deduplication
Handles out-of-order events using a defined sequence column—no manual window logic needed - Built-in change semantics
Supports INSERT, UPDATE, DELETE with SCD Type 1/2 via a few key parameters—no need for multiple MERGE clauses - Streaming-native
Designed for structured streaming, offering better performance, checkpointing, and transactional consistency - Simpler code & governance
Less boilerplate, fewer maintenance burdens, and cleaner pipeline definitions.
Example:

MERGE vs APPLY_CHANGES: Side-by-Side Comparison:
Feature | MERGE INTO | DLT APPLY CHANGES |
CDC semantics | Manual implementation required | Declarative I/U/D with SCD support |
Deduplication & order | Window functions + custom logic | Built-in via the sequence_by column |
Out-of-order handling | Manual pre-processing | Automatically handled |
Code complexity | High – multiple SQL/logic blocks | Low – simple declarative API |
Streaming native | Yes, but with manual checkpoints | Yes, optimized for streaming |
SCD Type support | Custom scripts required | Natively supports Type 1 & Type 2 |
Performance | Depends on manual tuning | Streamlined for efficiency |
Flexibility | Full control—joins, custom logic | Best for standard CDC; limited flexibility |
When to Use Which?
Choose MERGE INTO when:
- You require multi-table joins or complex business logic
- Managing non-standard SCD Type 2/3 transformations
- Running ad-hoc batch jobs or historical backfills
Choose APPLY CHANGES when:
- Building structured streaming/CDC pipelines with Delta Live Tables
- The CDC feed has a clear primary key and sequence column
- You want simplified, maintainable, and streaming-native CDC pipelines
Best Practices for DLT APPLY CHANGES
- Enable CDC source: Ensure your input Delta table uses Change Data Feed
- Choose keys and sequence: Clearly define unique keys and an ordering column
- Set delete semantics: Use apply_as_deletes to mark records for removal
- Choose SCD mode: default is Type 1; use stored_as_scd_type=”2″ for Type 2
- Monitor metrics like num_upserted_rows and num_deleted_rows to track pipeline health and performance
Conclusion
- Spark MERGE INTO delivers complete control and flexibility but entails significantly more engineering for ordering, deduplication, and performance tuning.
- DLT APPLY CHANGES offers a lean, declarative, and streaming-optimized alternative for CDC pipelines in Databricks, minimizing boilerplate and improving maintainability.
For most CDC workflows, especially streaming scenarios, APPLY CHANGES is the preferred choice. Save MERGE INTO for specialized cases that require custom logic or ad-hoc transformations.