
In today’s data-driven world, enterprises handle massive amounts of continuously arriving data from various sources. Google Sheets often serves as a quick and easy way for teams to manage and share data, especially for smaller datasets or collaborative efforts. However, when it comes to advanced analytics, larger datasets, or integration with other complex data sources, a robust data platform like Databricks becomes essential.
This blog post will guide you through the process of seamlessly ingesting data from Google Sheets into Databricks using Python and the gspread library. This integration will empower you to leverage Databricks for advanced analytics and robust data management, transforming your raw spreadsheet data into a foundation for deeper insights.
Challenges of Traditional ETL for Google Sheets Processing:
Traditional ETL pipelines, especially when dealing with data originating from flexible sources like Google Sheets, often present unique challenges:
- Manual export/import — Downloading CSVs and re-uploading is time‑intensive, error‑prone, and unscalable for frequent updates.
- No automation = stale data — If there’s no scheduled or automated update, your Google Sheet data stays outdated and forces manual refreshes.
- Data-type inconsistencies — Google Sheets stores number/text/date formats flexibly, leading to type mismatches during ETL.
- Schema drift — Adding columns in Sheets often breaks static ETL pipelines that assume fixed headers.
- Scalability limits — Large spreadsheets slow down, and manual ETL cannot handle bigger datasets.
- Security/access issues — Managing sharing manually via UI is error-prone, insecure, and hard to govern at scale.
Due to these limitations, organizations face increased engineering efforts to maintain data pipelines, risk data inconsistencies, and often lack timely insights from spreadsheet-bound data.
What is Databricks for Google Sheets Ingestion:
Databricks, powered by Apache Spark, provides a flexible and scalable environment to ingest data from various sources. For Google Sheets, we leverage the gspread Python library to programmatically extract the data. Once the data is retrieved and transformed into a Spark DataFrame, the powerful capabilities of Databricks can be utilized to store it efficiently in Delta Lake.
How Databricks Solves These Challenges:
By programmatically ingesting Google Sheets data into Databricks and storing it in Delta Lake, we address the traditional ETL challenges effectively:
- No manual overhead — The pipeline from Google Sheets to Delta Lake is fully scripted, removing manual exports/imports and minimizing human error.
- Automated ingestion — Schedule the notebook as a Databricks Job to refresh the Delta table regularly, eliminating stale data and manual intervention.
- Robust data handling — Loaded as a Spark DataFrame, the data can be cleaned, validated, and type-cast using Spark SQL or PySpark transformations.
- Scalable performance — Delta Lake adds ACID transactions, schema enforcement, scalable metadata, and fast query optimizations on top of Spark.
- Secure, centralized access — Service account credentials can be stored securely via Databricks Secrets, ensuring safe and governed access to Google Sheets.
This approach ensures automated, cost-efficient, and reliable data ingestion from Google Sheets for both ad-hoc analysis and regular reporting, eliminating the limitations of manual processes.
For Example: Step-by-Step ETL Pipeline
To set up the ingestion pipeline for your Google Sheet, follow these steps:
Step 1. Create and share a Google Service Account
- Use GCP Console → APIs & Services → enable “Google Sheets API”
- Create a Service Account and generate a JSON file
- Grant the service account Editor access to your Google sheet
Step 2: Save the generated JSON key file
The downloaded JSON file needs to be saved in a secure, accessible location within your Databricks environment or any cloud storage. For example, this might be a /Volumes path or DBFS. For production, Databricks Secrets are highly recommended for storing the content of this file.
Step 3: Install the gspread library
In a notebook cell:
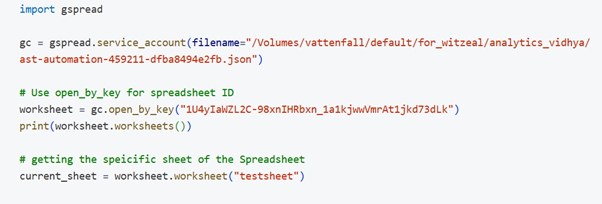
Step 4: Implementing the ETL for Google spreadsheet
- Importing the gspread library
- Use the filename parameter to point to the credentials JSON file in service_account.
- Give the spreadsheet ID and sheet name of the Google spreadsheet file
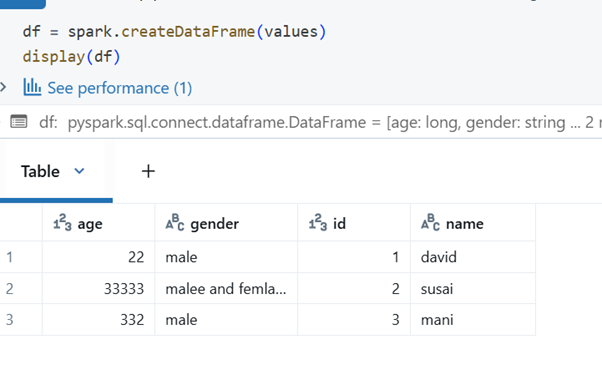
To retrieve Google Sheet data as a list of lists, use the get_all_values() function.

To retrieve Google Sheet data as a list of dictionaries, use the get_all_records() function.

Convert the data into a Spark DataFrame using createDataFrame()
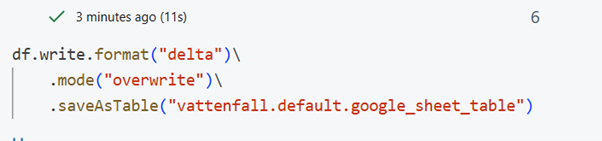
Write the Spark DataFrame to a Delta table
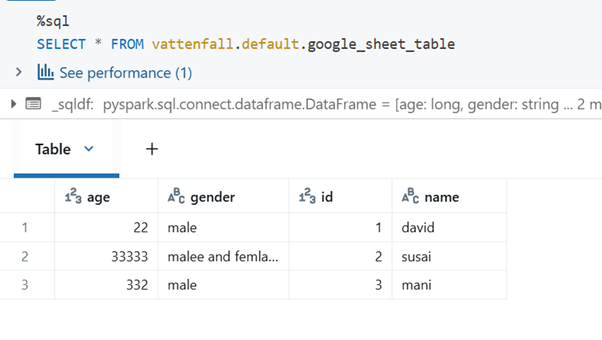
After writing the table, use a SQL query to retrieve the data from the table in Databricks.
Step 5: Schedule the Notebook as a Databricks Job (for automation)
For regular updates, schedule this notebook as a Databricks Job to run automatically.
- Go to Workflows > Jobs in your Databricks workspace.
- Click Create Job.
- Add a task, select Notebook, and choose your ingestion notebook.
- Configure the cluster and schedule as needed (e.g., daily, hourly).
Advantages of Using This Method for Data Processing:
- No Manual Metadata Tracking: The gspread library fetches the current state of the sheet, and the overwrite mode ensures the Delta table always reflects the latest data.
- Real-Time or Batch Processing: Although gspread is not a streaming API, it supports highly frequent batch updates that can mimic near-real-time data for many use cases.
- Lower Cost and Compute Efficiency: Leveraging Spark’s createDataFrame and Delta Lake’s efficient storage.
- Data Quality & Governance: Once in Delta, the data can be further processed and governed using Databricks’ robust features.
- Easy Integration: Works seamlessly with Databricks Delta Lake, ensuring smooth implementation and powerful capabilities for all subsequent data operations.
Conclusion:
Using a Python-based ingestion script with gspread to bring data from Google Sheets directly into a Delta table on Databricks is a powerful and efficient solution. This approach streamlines the creation and management of data pipelines by automating the extraction, transformation, and loading process. By eliminating manual steps and leveraging Databricks’ scalable environment, you can ensure data quality, reduce operational overhead, and make your spreadsheet data readily available for advanced analytics and machine learning. This method effectively transforms Google Sheets from isolated data silos into integrated components of your enterprise data lakehouse.
-David M
Data Engineer
Step 7: Verify the Migration
After the migration is complete, connect to your s3and verify that the database, tables, data, stored procedures, triggers, and events have been successfully migrated.
Step 8: (Optional) Delete DMS Resources
- Delete the DMS replication instance
- Remove the endpoints
- Retain or archive the S3 data as per your retention policy
- To prevent additional costs
Conclusion
Migrating from Amazon RDS to Amazon S3 with AWS DMS is a strategic and high-impact move toward building a modern, scalable, and analytics-ready data platform. With its ability to deliver near-zero downtime, continuous data replication, and cost-efficient storage, AWS DMS empowers you to accelerate digital transformation with confidence.
Unlock the full potential of your data infrastructure—kickstart your AWS DMS migration today and drive intelligent, data-driven outcomes!