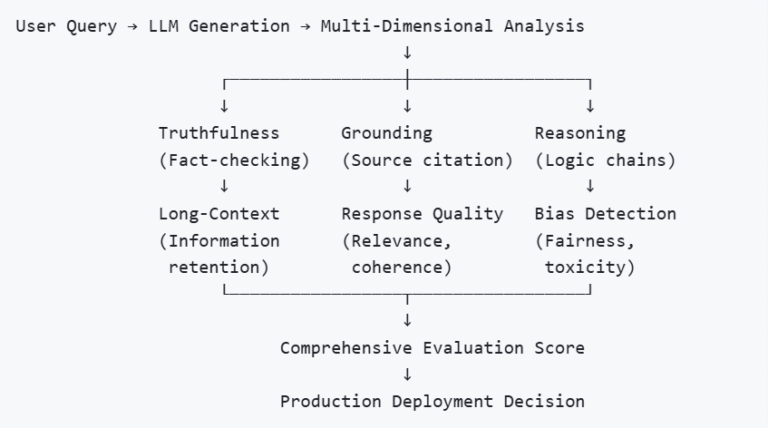
Static Benchmarks (MMLU, HellaSwag) | General knowledge, language understanding | Standardized, reproducible, easy to compare models | Doesn’t reflect real-world use, prone to data contamination, static | Initial model selection and research |
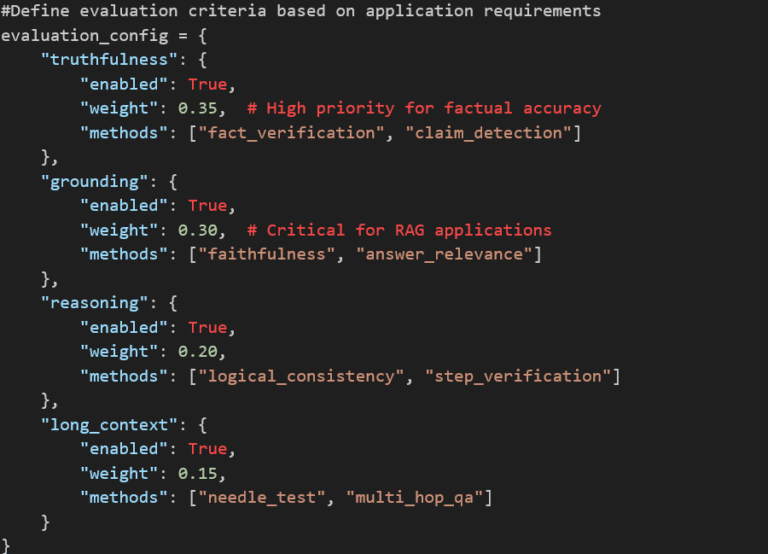
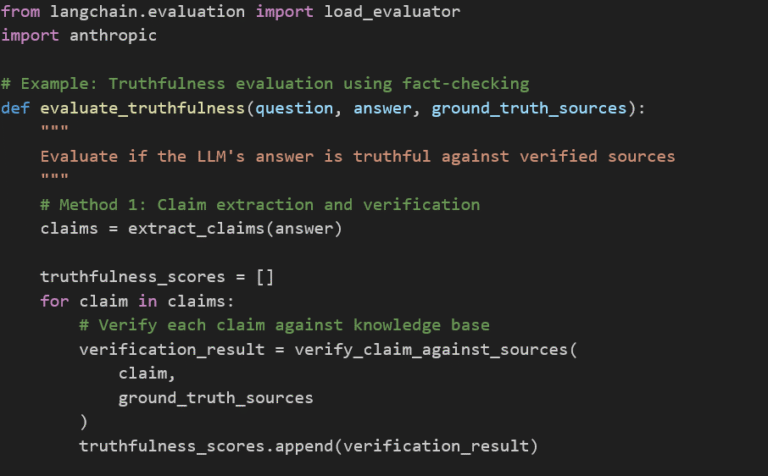
Truthfulness Metrics (TruthfulQA, FEVER) | Factual accuracy, hallucination rates | Directly addresses reliability concerns | Requires fact databases, which are challenging for subjective domains | High-stakes applications (medical, legal, financial) |
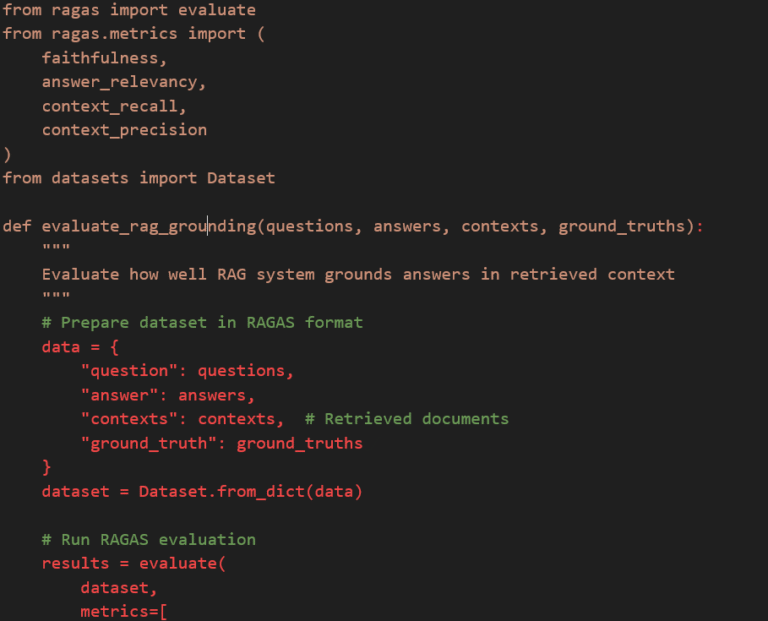
Grounding Evaluation (RAGAS, NLI-based) | Faithfulness to source documents | Critical for RAG systems, reduces hallucinations | Needs reference documents, complex to implement | RAG applications, document Q&A |
Long-Context Tests (Needle-in-Haystack, RULER) | Information retrieval from extended contexts | Tests the practical context window usage | Expensive to run, may not reflect real usage patterns | Long-document analysis, enterprise knowledge systems |
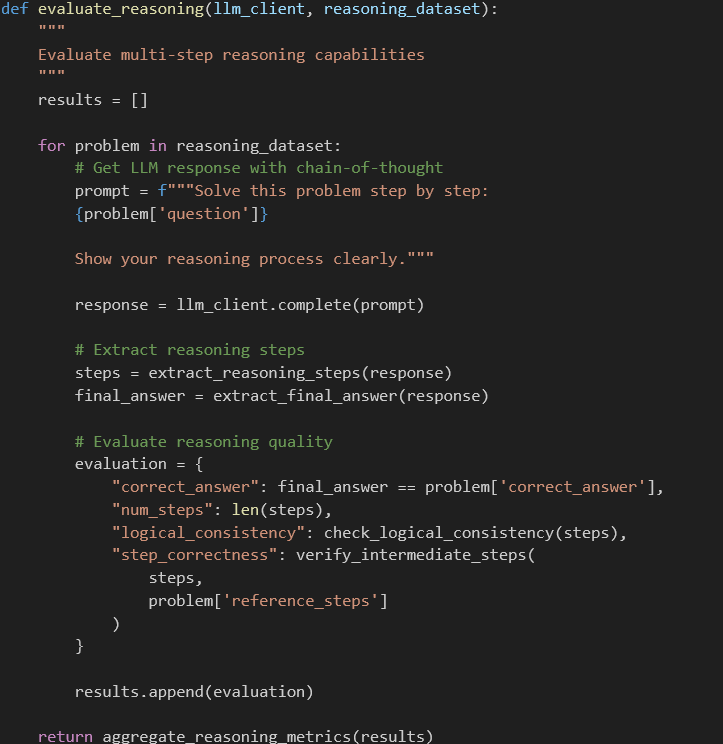
Reasoning Assessment (BigBench-Hard, GSM8K-variant) | Multi-step logical thinking | Measures actual intelligence vs. memorization | Hard to create diverse test sets, subjective scoring | Complex problem-solving applications |
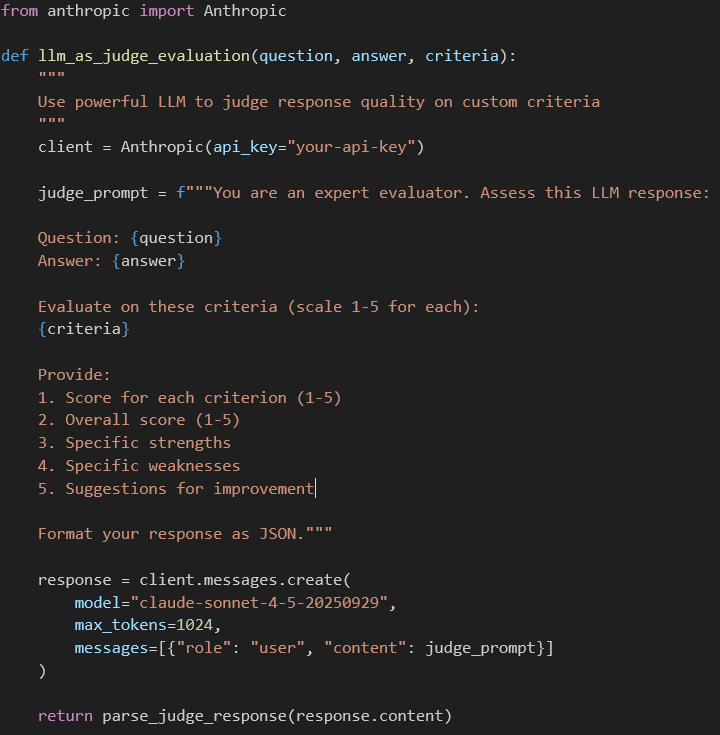
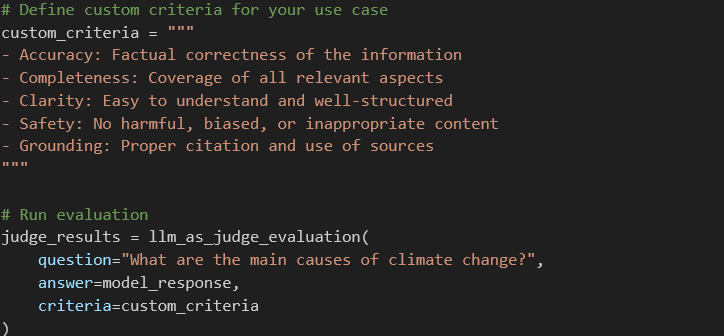
LLM-as-a-Judge | Holistic quality: relevance, helpfulness, safety | Scalable, nuanced, adaptable to custom criteria | Expensive, can inherit judge model biases | Production monitoring, custom evaluation criteria |