
Identifying and removing duplicate records is essential for maintaining data accuracy in large-scale datasets. This guide demonstrates how to leverage PySpark’s built-in functions to efficiently clean your data and ensure consistency across your pipeline.
Predominant methods to remove duplicates from a dataframe in PySpark are:
- distinct () function
- dropDuplicates() function
- Using the Window function
- Using group by along with aggregation and join
Current Challenges Without Removing Duplicates
- Inconsistent data produces faulty insights and imprudent decision-making.
- Accurate planning and company reporting are impacted by inflated metrics and KPIs.
- Unnecessary memory usage by redundant data drives up storage prices.
- Large joins and aggregations over duplicate data cause the query to perform more slowly.
- To account for unhandled duplicates, more logic is needed downstream (such as filters or aggregations).
When normalization is not done properly, it can also lead to data redundancy and duplicate records within tables. This compromises data quality and increases storage and processing costs. To address this issue in PySpark, functions like distinct() and dropDuplicates() are essential tools for identifying and removing duplicates, ensuring clean and reliable data for downstream processing.
Let’s now see what normalization is and how the data evolves across each normalization type.
Normalization is the process of organizing data to eliminate redundancy and improve data integrity by dividing a table into smaller related tables.
Normal Form | Goal | Explanation |
1NF | Eliminate repeating groups | Ensures that all columns contain only atomic (indivisible) values, and each record is unique. No arrays or nested structures. |
2NF | Eliminate partial dependency | Builds on 1NF. All non-key attributes must depend on the entire primary key, not just part of it (applies to composite keys). |
3NF | Eliminate transitive dependency | Ensures that non-key attributes depend only on the primary key and not on other non-key attributes. |
BCNF | Handle special cases of 3NF | A stricter version of 3NF where every determinant (column that determines another) must be a candidate key. |
4NF | Eliminate multi-valued dependency | Prevents a record from containing two or more independent multi-valued facts about an entity. |
5NF | Eliminate join dependency | Ensures data is broken into smallest possible units that can be joined without introducing redundancy. Used for complex data models. |
Below are the ways in which incorrect Normalization can introduce Duplicates in your data:
Partial or Incomplete Normalization – Failing to separate repeating groups or multi-valued attributes (e.g., keeping multiple phone numbers in one row) can lead to data being copied across rows.
Missing or Incorrect Primary Keys – Without proper keys or constraints, duplicate records with the same business meaning may be inserted unknowingly.
Incorrect Joins Between Tables – Joining tables on non-unique or incorrect keys can lead to a Cartesian product, duplicating rows unexpectedly.
Storing Derived Data – Storing computed values in a table (e.g., totals, ranks) that aren’t maintained consistently leads to duplication when source data changes.
What are the distinct () and dropDuplicates() functions in PySpark?
The distinct () function removes completely duplicate rows across all columns. This is used when you want to remove rows that are identical across every column in a dataframe.
The dropDuplicates() function removes duplicates based on a specific column or a list of columns. This is used when only certain columns determine uniqueness.
When to Use Which Method?
Use distinct ():
- When you need to remove duplicates across all columns.
- When you have a smaller dataset, or performance is not a critical concern.
Use dropDuplicates():
- When you need to remove duplicates based on specific columns.
- When you need more control and flexibility over which duplicates to remove.
- When dealing with large datasets and optimizing performance is important.
Handling Null Values: Both methods treat null values as equivalent. For example, two rows with nulls in the same column will be considered duplicates and only one will be retained.
When you use distinct() or dropDuplicates(), internally Spark handles duplicates using below steps:
Step 1: Hash partitioning
PySpark computes a hash for each row in the data you have in your DataFrame or RDD. This hash is used to determine whether two rows are identical.
Step 2: Shuffling
The data is shuffled across the cluster to group identical rows together based on their hash values.
Step 3: Deduplication
After shuffling, only one copy of each unique row is retained, effectively removing duplicates.
Code Snippet to show distinct() functionality:

Output:
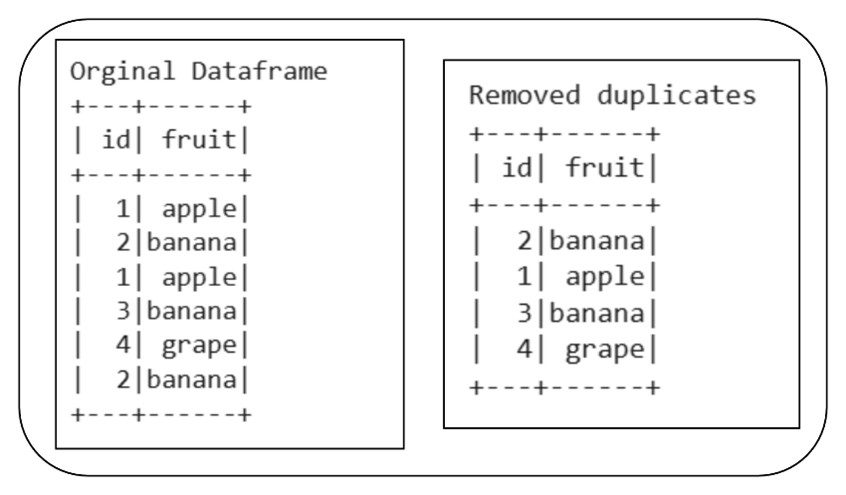
Spark assigns a hash key internally for every row after using the distinct() method. Then, identical rows are redistributed around the cluster according to their hash values. After that, the duplicate rows are dropped while keeping the first occurrence of the duplicated row found. Then shows the outcome without any duplicates.
Thus, when the distinct() method is used, what Spark does internally here:
- Uses hashing on the full row.
- Shuffles data so identical rows come together.
- Keeps one copy per unique row.
Code Snippet to show dropDuplicates() functionality:
Here, we only de-duplicate based on the column we specify in the dropDuplicates() function.
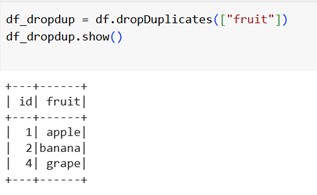
Thus, we can sum up the internal behaviour of Spark as follows:
|
While distinct() and dropDuplicates() are the two inbuilt methods used to remove duplicates. The methods below are the most powerful and customizable ways to remove duplicates based on a timestamp column present in the table.
- group by + max() + join
- window function + row_number()
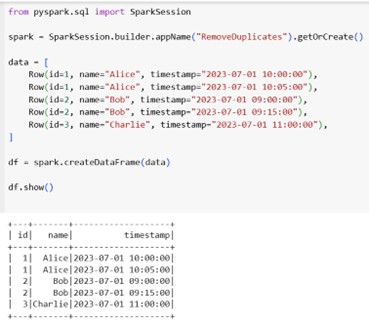
Using group by + max() + join function :
We can perform aggregation based on the date column and leverage the group by functionality on the unique key column. Then, to obtain the result, utilize the join function to extract every row from the dataframe.
Code Snippet:
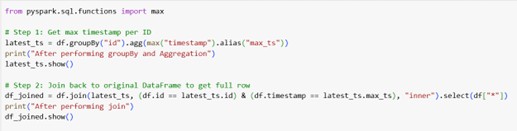
Output:

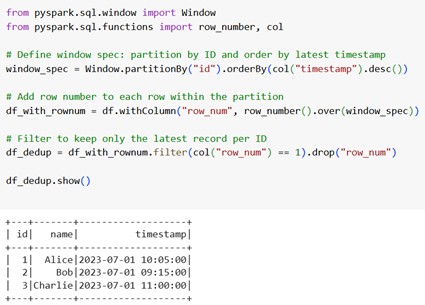
Using window function + row_number()
This is more flexible and often used when:
- You want to keep the latest record based on a timestamp.
- You want to retain only one row per group based on some ordering logic.
Code Snippet:
When to use What
Method | Best Scenario | Retains information of all columns, Full Row? | Accomplish custom logic |
.distinct() / .dropDuplicates() | When you just want to remove exact duplicates. | Yes | No |
Window + row_number() | When you want the top N or the first row by some logic. | Yes | Yes |
groupBy + agg() | When you only need aggregated column values. | No | Yes |
groupBy + join | When you need a full row with max/min/specific field. | Yes | Yes |
Summary:
This blog explored multiple techniques to remove duplicates in PySpark, including distinct(), dropDuplicates(), window functions, and groupBy with aggregation and join. Choosing the right deduplication method depends on the data context—such as whether full-row uniqueness is needed, or duplicates are based on specific columns. Understanding these methods helps ensure clean, consistent, and efficient data pipelines.