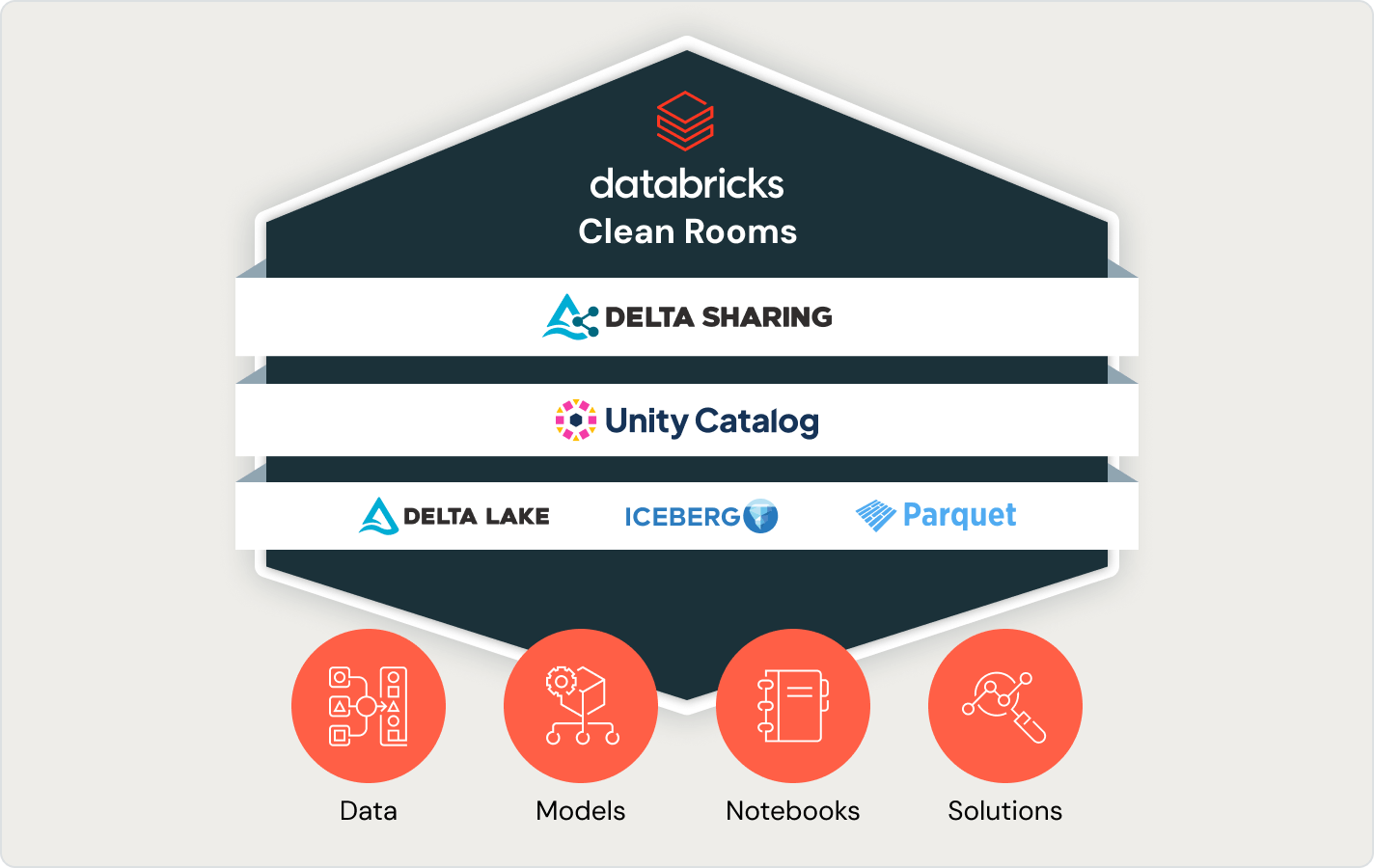
A Data clean Room is a secure space that enables businesses to work together on sensitive data without exposing or compromising it. By using robust protocols and advanced technologies it allows multiple parties to combine and analyse information while ensuring strict adherence to privacy regulations and compliance requirements.
Let’s consider a scenario where two organizations (e.g., Bank A and Bank B) want to collaborate on data analysis to detect fraudulent transactions.
- Each bank holds sensitive customer information (names, account numbers, transaction details) and data assets (fraud indicators, transaction patterns).
- Direct sharing is not allowed due to compliance laws.
- Traditional collaboration involves manual extraction, anonymization, and secure file transfers.
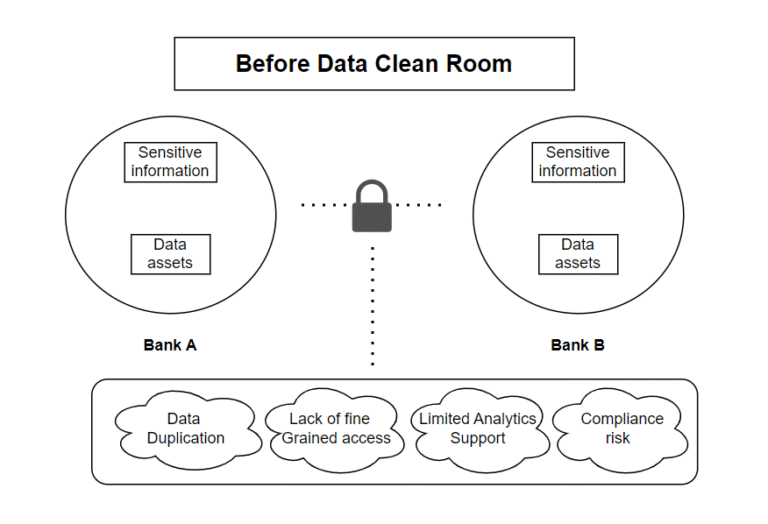
Challenges Before the Existence of the Data Clean Room:
- Data Duplication: Due to the need to export and duplicate data into external systems for partners, there were more unmanaged copies of the same data, which increased storage costs.
- Lack of Fine-Grained Access Controls: Access to certain columns, rows, or functions could not be restricted by organizations. Sharing only aggregated or disguised data becomes challenging as a result, raising the possibility of disclosing private or sensitive information.
- Limited Advanced Analytics Support: The use of collaborative analytics was limited to simple reporting. The absence of cross-platform processing capabilities and security limitations made it impossible to run ML models or do real-time analytics across partner datasets.
- Compliance Risk: Even after anonymization, shared data can unintentionally expose sensitive insights. Subtle patterns or cross-referencing with other data sources might still reveal identities or confidential details, posing compliance risks.
Let’s kick off the blog with a real-world scenario that illustrates the need and emergence of Data Clean Rooms.
We have Bank A and Bank B. Within these banks, fraudsters often move stolen money across banks to avoid detection.
- Bank A notices a suspicious transaction pattern from its customers.
- Bank B also sees similar unusual deposits from unknown sources.
- Individually, neither bank has enough data to confirm fraud because the suspicious pattern only emerges when both datasets are combined.
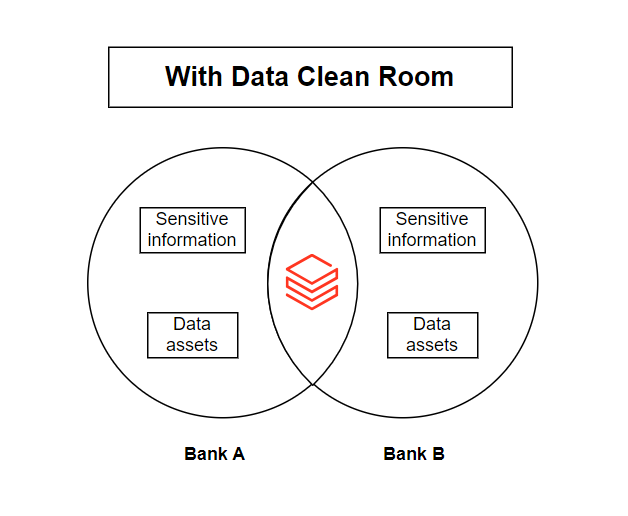
However, privacy regulations prevent them from directly sharing sensitive customer information. To overcome this, they decide to use a Data Clean Room, a secure environment where they can jointly analyse data without exposing the underlying PII by following the steps below.
Step 1: Bank A provides a pre-built analysis notebook inside the clean room.
Step 2: Bank B runs this notebook on the combined anonymized datasets from both banks.
Step 3: The notebook aggregates patterns such as:
- Number of high-value transfers from Bank A accounts to Bank B accounts within short time windows.
- Frequency of cash withdrawals soon after deposits.
Step 4: From these aggregated metrics, Bank B observes a clear pattern of suspicious fund movements, which are the fraud indicators, without ever seeing Bank A’s sensitive customer data.
Features of the Data Clean Room:
Privacy-Preserving Collaboration
- It enables joint analysis without exposing raw or personally identifiable information (PII) by using masking, anonymization, and privacy rules.
- It ensures compliance while keeping sensitive data secure.
No Data Movement
- In a clean room setup, all data remains within the data owner’s cloud environment, avoiding duplication and minimizing the need for complex ETL processes.
- Analysis is performed directly on live, current datasets, ensuring results are always based on the most up-to-date information.
Built on Delta Sharing
- Uses an open, cross-cloud protocol with full ACID compliance, ensuring reliability and preventing vendor lock-in.
- Enables seamless collaboration between parties, regardless of the platforms or cloud providers they use.
Fine-Grained Access Control
- Unity Catalog manages permissions at the row, column, and function level, ensuring fine-grained access control.
- Comprehensive auditing and encryption are in place to maintain strict governance and data security.
Advanced Analytics & ML Support
- Securely run SQL, Python, Spark, and machine learning workloads on scalable, serverless compute infrastructure.
- Integrates with BI tools and efficiently handles analysis on large-scale datasets.
Key Takeaways:
- Private, Collaborative Computation – Databricks Clean Room enables two or more parties to securely bring in their data assets, notebooks, unstructured data, and even AI models, agree on a computation, and share only the results with the intended recipient—without revealing raw data.
- Beyond SQL-Only Clean Rooms – Unlike many clean room solutions that limit collaboration to SQL queries, Databricks Clean Room supports sharing of data assets, notebooks, SQL scripts, and AI models. Built on Delta Sharing and integrated with Lakehouse Federation, it enables seamless cross-cloud and cross-platform collaboration.
- Controlled Notebook Execution – When Contributor A shares a notebook or AI model, it must first be approved by Contributor B. Once approved, Contributor B can execute it to securely combine datasets from both parties and generate visualizations or aggregated results, without exposing raw data.
- Metadata-Only Data Visibility – When a data asset is shared, collaborators see only the metadata (such as table schema and column names) but not the actual underlying data.
- Isolated & Secure Execution Environment – All computations occur in a secure, isolated environment, ensuring that neither party’s compute resources are used for running the shared notebooks.