Understanding Power BI Workspace Roles: Simplifying Collaboration in Analytics
Introduction Managing team collaboration and data security is critical in modern analytics. Power BI Workspaces offer an efficient way for teams to build, share, and manage reports and dashboards. Microsoft Power BI introduces 4 workspace roles – Admin, Member, Contributor, and Viewer – each with specific capabilities to ensure smooth operations. In this article, we’ll […]
Liquid Clustering in Databricks: The Future of Delta Table Optimization
Introduction — The Big Shift in Delta Optimization In the ever-evolving world of big data, performance tuning is no longer optional – it’s essential. As datasets grow exponentially, so does the complexity of keeping them optimized for querying. Databricks’ Liquid Clustering is a groundbreaking approach to data organization within Delta tables. Unlike traditional static partitioning, […]
Transitioning From LLM Chatbots to AI Agents: The Revolutionary Shift in Enterprise Automation in 2025

Remember when asking Siri to set a timer felt like magic? Today, AI systems are autonomously managing entire business workflows, making strategic decisions, and executing complex multi-step processes without human intervention. The global AI agent market is projected to explode from $5.1 billion in 2024 to $47.1 billion by 2030—but what’s driving this seismic shift […]
Seamless Power BI Report Management with OneDrive/SharePoint Integration

Managing Power BI reports across teams can quickly become complex without the right tools. By integrating OneDrive or SharePoint with Power BI, you streamline version control, collaboration, and report deployment — all without repetitive manual publishing. Session Objectives Understand the integration between Power BI and OneDrive/SharePoint. Learn how to manage and update Power BI reports […]
UDF vs Inbuilt Functions in PySpark — The Simple Guide

If you’re working with PySpark, you’ve probably asked yourself this at some point: “Should I use a built-in function or just write my own?” Great question — and one that can have a huge impact on your Spark application’s performance. In PySpark, there are two main ways to transform or manipulate your data: Using Inbuilt […]
Apache Spark 4.0’s Variant Data Types: The Game-Changer for Semi-Structured Data

As enterprises increasingly rely on semi-structured data—like JSON from user logs, APIs, and IoT devices—data engineers face a constant battle between flexibility and performance. Traditional methods require complex schema management or inefficient parsing logic, making it hard to scale. Variant was introduced to address these limitations by allowing complex, evolving JSON or map-like structures to […]
PIM and DIM what’s the difference, and why do you need both?

What is PIM (Product Information Management)? PIM is software that centralizes, manages, and enriches product data for marketing and sales across various channels. Think of PIM as your product data brain: Product names, descriptions SKU numbers Technical specs (size, weight, material) Prices and availability Localized language info Product categorization Relationships between products (e.g., bundles, accessories) […]
Turning Notebooks into Dashboards with Databricks
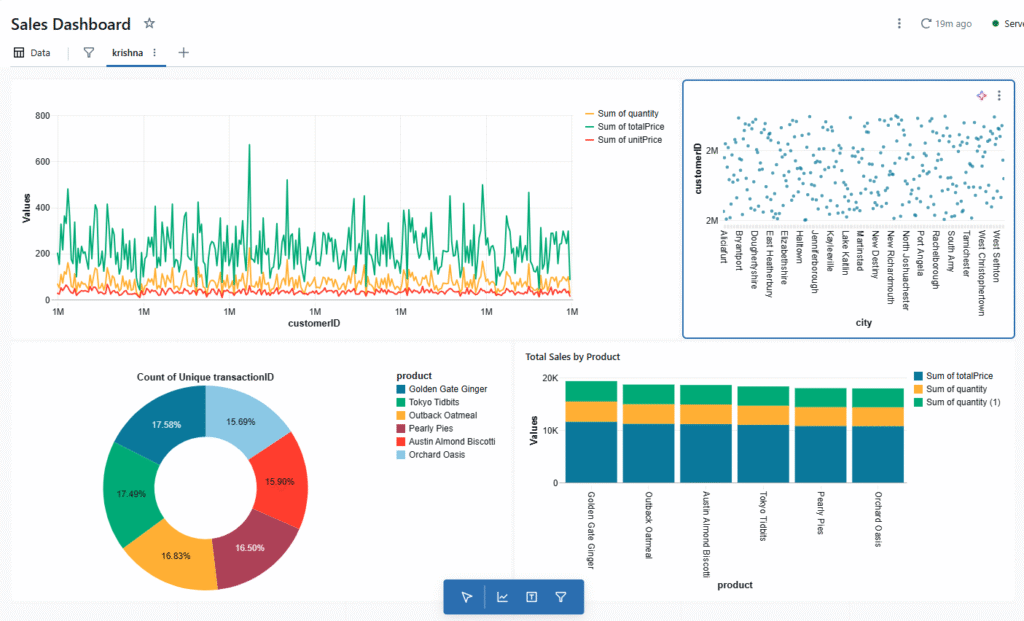
Why Databricks Notebook Dashboards Stand Out In the world of data-driven decision-making, dashboards are essential for turning raw numbers into actionable insights. While most dashboards help you visualize numbers, Databricks takes it a step further by making the process smooth, flexible, and tightly integrated with your working environment. Databricks notebook dashboards offer a unique blend […]
Creating Dynamic Forms Using React

Introduction React is an open-source JavaScript library created by Facebook in 2013, used extensively to construct contemporary front-end applications. It takes a component-based approach, enabling developers to construct reusable, interactive, and dynamic user interfaces with minimal effort. This makes it easier to segment complicated UIs into smaller components that contain both logic and structure. One […]
Ensuring Data Quality in PySpark: A Hands-On Guide to Deduplication Methods

Identifying and removing duplicate records is essential for maintaining data accuracy in large-scale datasets. This guide demonstrates how to leverage PySpark’s built-in functions to efficiently clean your data and ensure consistency across your pipeline. Predominant methods to remove duplicates from a dataframe in PySpark are: distinct () function dropDuplicates() function Using the Window function Using […]