End-to-End Ingestion of 400+ MySQL Tables with Databricks Delta Live Tables
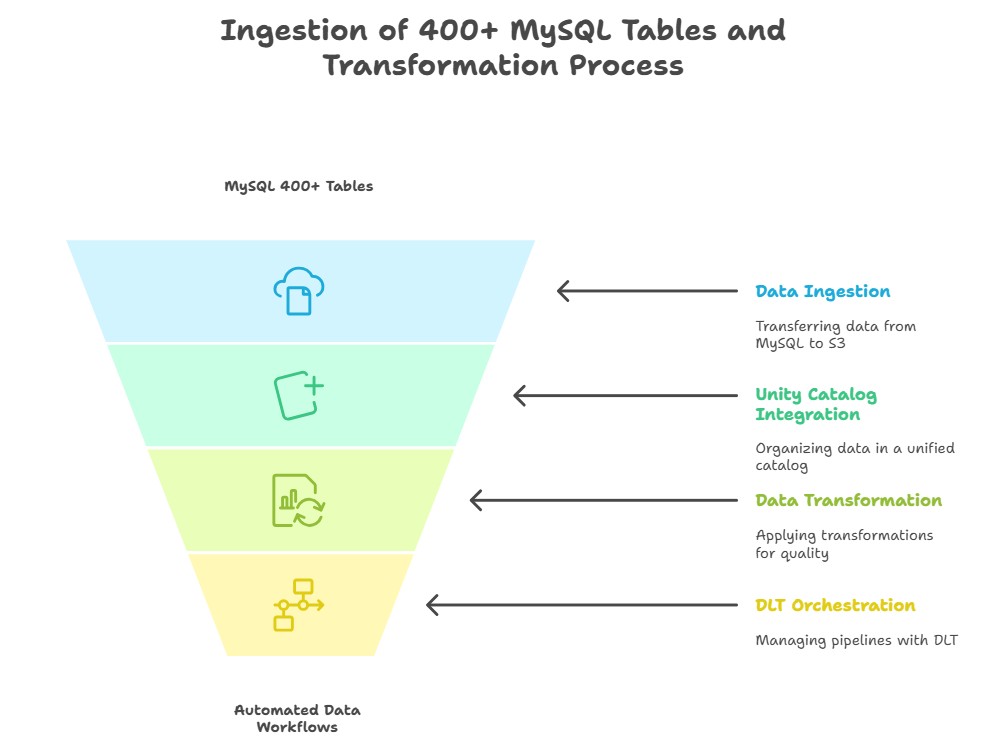
Ingesting and managing data from more than 400 MySQL tables on recurring schedules is a complex challenge. Traditional approaches often lead to pipelines that are difficult to scale, hard to maintain, and prone to failure when handling schema changes or scheduling dependencies. To address these challenges, we designed and implemented a configuration-driven ingestion framework using […]
What Is Data Science Consulting 2025? A Beginner’s Guide

Data has become a crucial component of nearly every business. Companies are collecting, storing, and analyzing a huge amount of data every second. They do this to make better business decisions and achieve success. Data science is becoming a key part of this. Businesses use algorithms, statistical models, and machine learning to understand their data. […]
10 Benefits of Hiring a Data Visualization Consultant in 2025

When it comes to hiring a data visualization consultant in 2025 supports businesses transform complicated data sets into clear and actionable insights. From knowing market trends and enhancing functional efficiency to strengthening business intelligence, these experts play a vital role. They help make data-driven decisions with consulting services and modern tools. The Importance of Hiring […]
Data Science Consulting vs In-House: Which to Choose?

Data science has become a popular term for businesses. It helps them grow, improve efficiency, and gain a competitive edge. As data is more accessible, businesses have two options for developing their data science skills. They can create an in-house team. Alternatively, they can hire a data science consulting firm. While both approaches have their […]
Function Calling, Tools & Agents: The Next Layer of LLM Intelligence

From Text Generation to Real-World Action: Imagine asking an AI to book a flight, check your calendar, and send confirmation emails all in a single conversation. Until recently, this scenario required multiple apps, manual coordination, and countless context switches. But what if your AI could seamlessly orchestrate these tasks autonomously? In 2025, an AI agent […]
Implementing Object-Level Security in Power BI Desktop

With the introduction of the Tabular Model Definition Language (TMDL) view in Power BI Desktop, implementing Object-Level Security (OLS) has become significantly more streamlined. Traditionally, OLS required the use of third-party tools such as Tabular Editor, making the process more complex. Now, OLS can be applied directly within Power BI Desktop, providing a more secure […]
Secure API Integration in Python Using Multiple Authentication Methods (with Azure Key Vault Support)
APIs are the backbone of modern applications, enabling seamless integration between different systems. However, interacting with APIs often requires authentication, which varies across APIs. In this article, I’ll show you how to build a reusable Python function that supports Bearer Token, Basic Authentication, and APIs that require no authentication. By the end, you’ll have a handy function […]
Human-Centered Design in an AI-Driven World: Why People Still Come First

In the age of artificial intelligence, the most crucial design principle remains human-centricity. This article explores why keeping people at the center of AI design leads to more ethical, effective, and valuable technology solutions. As artificial intelligence transforms how we interact with technology, a critical question emerges: How do we ensure these powerful systems serve […]
Why More Tools Fail to Make Better Agents: Escaping the Trap of Tool Hell

If one tool makes an agent powerful, wouldn’t twenty make it unstoppable? Not really. Just like a person standing in front of 100 TV channels but unable to decide what to watch, an AI agent with too many tools often freezes, makes the wrong call, or wastes time. That is the trap of Tool Hell. […]
Serverless Web Apps: What, Why, and How

The landscape of web development is constantly evolving. One of the most exciting shifts in recent years is the rise of serverless architecture—a model that frees developers from managing infrastructure. Whether you’re building a static site, a full-stack app, or an API-driven service, serverless web apps offer speed, scalability, and simplicity like never before. But […]