Idempotency in Rest APIs: Why It Matters

What is Idempotency? Idempotency means that making the same API request multiple times has the same effect as making it once. In other words, no matter how many times you repeat the request, the result and the state of the server remain unchanged after the first successful call. Why is Idempotency Important? Prevents duplicate actions: […]
DAX Context Types Explained: Row Context vs Filter Context vs Query Context
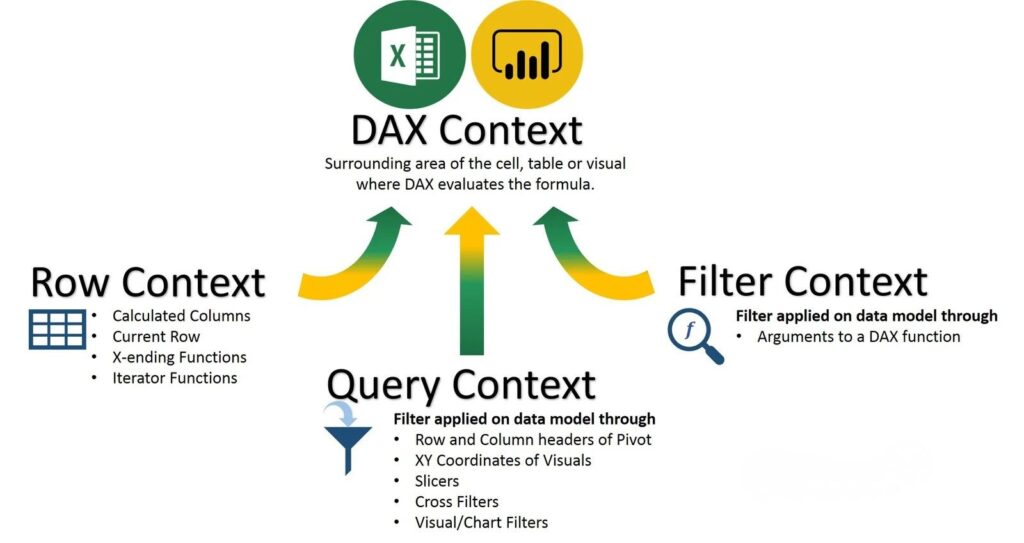
One of the most fundamental — yet confusing — concepts in DAX is context. Understanding how Row Context, Filter Context, and Query Context work is the key to writing accurate, powerful, and optimized DAX formulas. In this blog, we’ll break down each context type, provide clear real-world examples, and explore how they interact in Power […]
Verify, Trust, Comply: The Future of Responsible AI on Databricks

Regulators expect timely, accurate disclosures; investors demand transparent ESG performance; customers reward brands that do the right thing and prove it. Yet inside most enterprises, compliance is chaotic, with internal data scattered across finance, supply chain, HR, and operations. Databricks helps break down these silos, unifying enterprise data on a single platform so organizations can […]
Talk Data to Me: Conversational AI Meets the Data Intelligence with Databricks

In today’s data-driven world, businesses sit on mountains of data, but turning raw data into actionable insights remains a major challenge. Multiple siloed systems, fragmented datasets, and the sheer complexity of analysis often leave organizations paralyzed, unable to extract meaningful insights promptly. Decision-making slows, opportunities are missed, and teams are bogged down in manual data […]
Seamless Ingestion from Google Sheets to Databricks: A Step-by-Step Guide

In today’s data-driven world, enterprises handle massive amounts of continuously arriving data from various sources. Google Sheets often serves as a quick and easy way for teams to manage and share data, especially for smaller datasets or collaborative efforts. However, when it comes to advanced analytics, larger datasets, or integration with other complex data sources, […]
Building a Real-Time Chat App With Websocket and Node.JS

Want to build a live chat app like WhatsApp or Messenger? In this blog, we’ll show you how to create a simple real-time chat app using Node.js and WebSocket, with easy code samples and explanations. What are WebSockets? WebSockets are a way to create a continuous connection between the client (browser) and server. Unlike HTTP, […]
Deep Copy vs Shallow Copy in Databricks Delta Lake
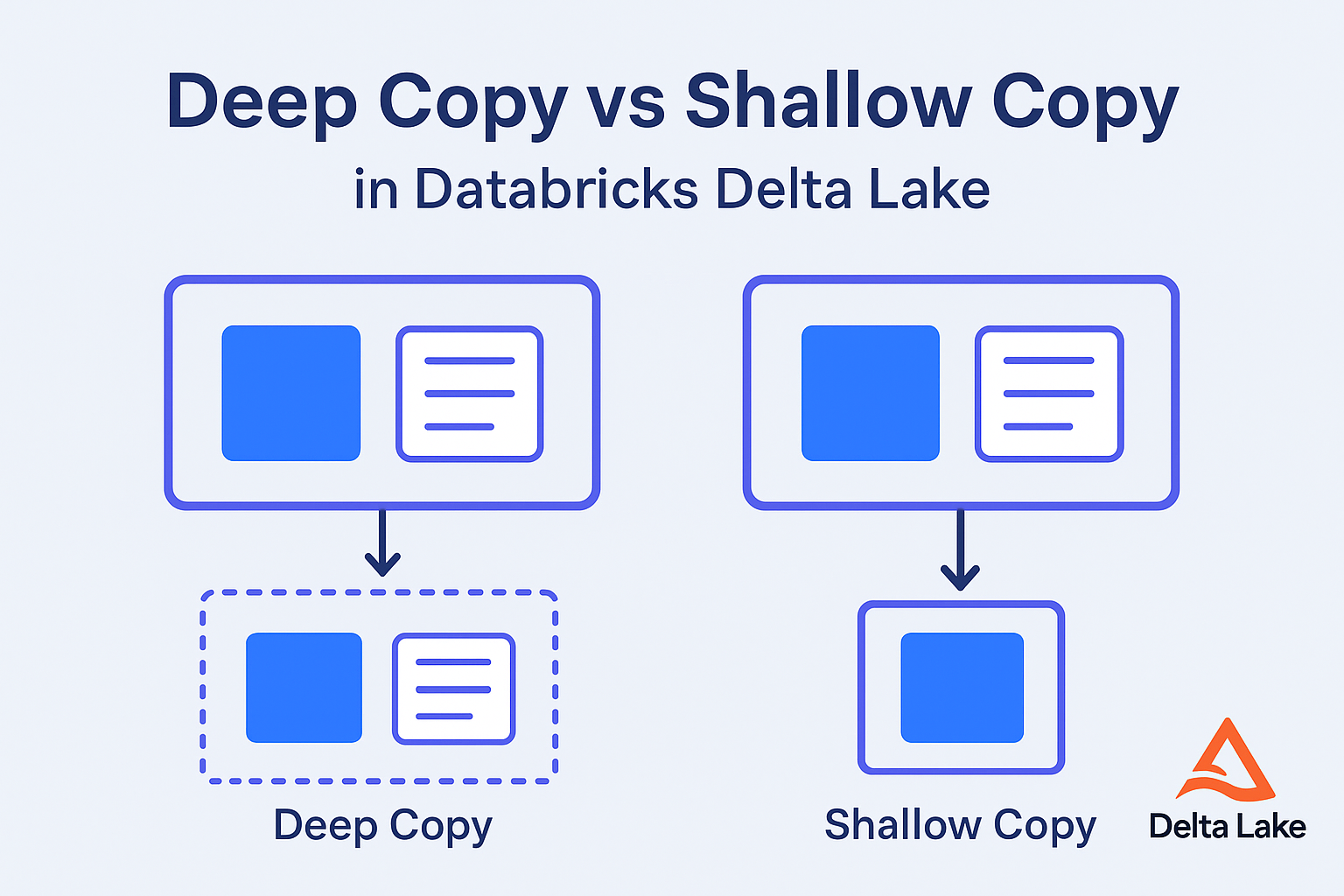
When working with large-scale data in Databricks Delta Lake, it’s common to create copies of tables for testing, development, or archival purposes. However, not all copies are created equal. In Delta Lake, shallow copy and deep copy serve different purposes and have very different behaviors — both in terms of performance and data isolation. In […]
The Hidden Wall Between Fabric OneLake and Databricks Unity Catalog
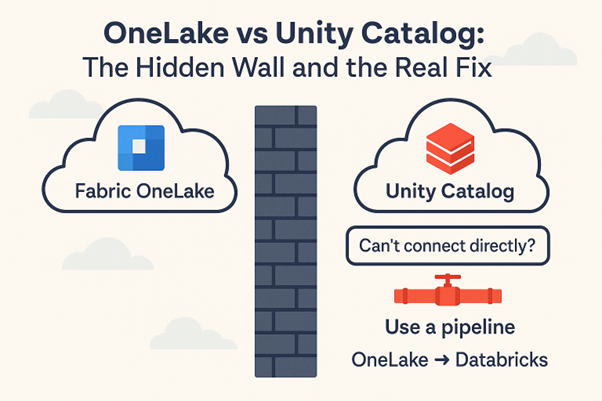
These days, many teams use Microsoft Fabric OneLake for unified storage and Databricks Unity Catalog (UC) for data governance and analytics. But here’s the catch: when you try to connect them directly, you hit a wall. You can’t simply register a Fabric Lakehouse as an external location in Databricks Unity Catalog like you would with […]
Getting Started with Kubernetes

Kubernetes has become the go-to platform for container orchestration, enabling developers and operations teams to deploy, manage, and scale containerized applications efficiently. If you’re new to Kubernetes, this guide will walk you through the basics, from what Kubernetes is to how to set up your first cluster and deploy an application. What is Kubernetes? Kubernetes, […]
Why Choose Django? A Beginner’s Guide to the Framework

Django is a high-level web framework for Python that enables developing dynamic websites more quickly and easily. Written with the “Don’t Repeat Yourself (DRY)” philosophy, it encourages reusable components and less code to write. With robust built-in features like user authentication, database integration, and CRUD operations ready to use out of the box, Django lets […]