
As enterprises increasingly rely on semi-structured data—like JSON from user logs, APIs, and IoT devices—data engineers face a constant battle between flexibility and performance. Traditional methods require complex schema management or inefficient parsing logic, making it hard to scale. Variant was introduced to address these limitations by allowing complex, evolving JSON or map-like structures to be stored in a single column—without sacrificing query performance.
Why Variant Is Essential for Data-Driven Media Platforms:
- Data Engineers working with diverse data sources and evolving schemas
- Analytics Engineers building flexible data pipelines for changing business requirements
- Data scientists who need to explore and analyze semi-structured data efficiently
- Platform Architects designing scalable data infrastructure for modern applications
Current Challenges:
- Performance Degradation: Traditional JSON string processing can be 5-10x slower than structured data operations, creating bottlenecks in real-time analytics pipelines.
- Schema Evolution Nightmares: Adding new fields or changing data structures requires complex migration processes, often resulting in downtime and data quality issues.
- Resource Waste: Inefficient storage formats lead to higher cloud costs and longer processing times, particularly problematic for organizations processing terabytes of semi-structured data daily.
- Development Complexity: Teams spend significant time writing custom parsing logic and handling schema inconsistencies instead of focusing on business value creation.
Understanding Variant Data Types:
Variant is a native data type purpose-built for semi-structured data. It allows storing, indexing, and efficiently querying deeply nested fields—directly within Spark.
Variant data types are a specialized storage format designed to handle semi-structured data (like JSON documents, XML files, log entries, and NoSQL database records) efficiently. Unlike traditional string-based JSON storage or rigid schema enforcement, Variant provides a middle ground that combines the flexibility of schemaless data with the performance benefits of structured storage.
Key features:
- Schema flexibility: No need to define explicit schemas upfront
- Efficient storage: Optimized binary format for faster access
- Native querying: Direct access to nested fields without parsing overhead
- Type preservation: Maintains original data types during storage and retrieval
- Variant Binary Format: Enables schema-less storage with better performance than JSON strings.
- Metadata Layer: Automatically tracks data types and structure without an explicit schema.
- Query Optimization: Speeds up nested field access and filtering with built-in optimizations.
Comparison of Data Handling Approaches
Approach | Flexibility | Performance | Schema Evolution | Query Complexity | Storage Efficiency |
String-based JSON | High | Low | Easy | High | Poor |
Strict Schema | Low | High | Difficult | Low | Excellent |
Variant Data Type | High | High | Easy | Low | Good |
Nested Structs | Medium | Medium | Medium | Medium | Good |
Practical Implementation
Step-by-Step Implementation Guide
1. Environment Setup
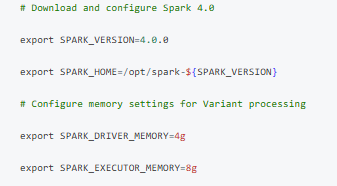
First, ensure you’re running Apache Spark 4.0 or later with proper configuration:
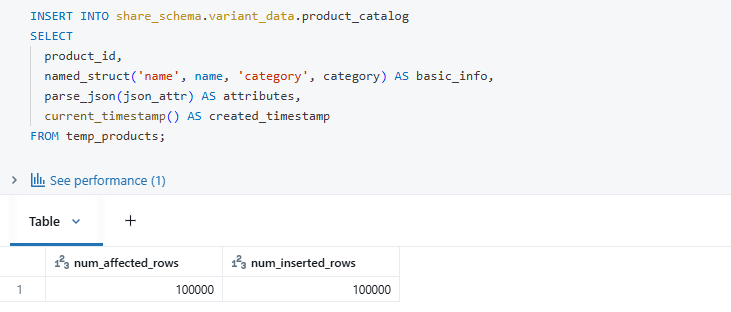
2. Creating Tables with Variant Columns

Insert sample data with different datatype structures
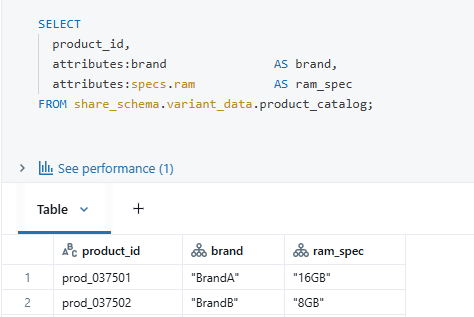
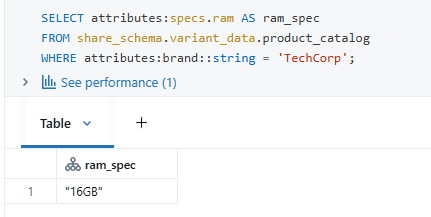
3. Querying the nested column, which is of a variant datatype:
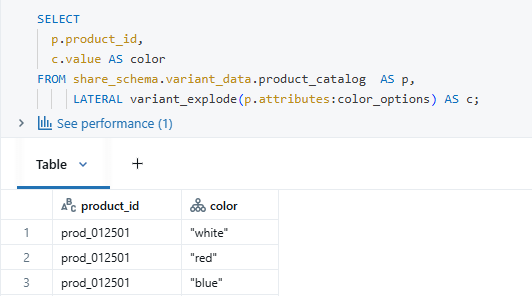
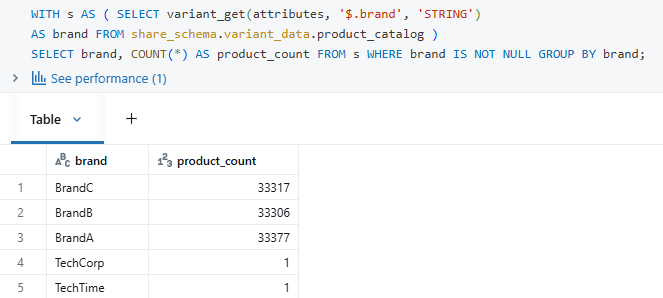
4. Performance Optimization Configuration:

Description:
These Spark configurations enable Adaptive Query Execution (AQE) to optimize performance while querying on VARIANT data. They dynamically adjust partitioning, coalesce skewed joins, and tune shuffle partitions to handle semi-structured data more efficiently.
Performance improvement:
- Partition Strategy: Organize data by frequently queried fields that exist outside the Variant column to minimize scanning overhead.
- Selective Field Access: Use specific field paths rather than retrieving entire Variant objects when possible.
- Early Filter Application: Apply conditions on VARIANT fields as early as possible in the query to enable Spark’s optimizer to reduce data processing and improve performance.
- Caching Strategy: Cache frequently accessed Variant data in memory, but be mindful of memory usage due to the flexible nature of the data.
Industry Use Case: Netflix’s Metadata Revolution with Variant Data Type
The Challenge:
Netflix handles millions of metadata records daily, each varying by content type (movie, series, documentary) and region. Managing this diversity with a rigid schema was inefficient.
Before the use of the Variant Data type resulted in Rigid Schema Complexity:
- Used 47+ separate tables (e.g., movies_metadata, series_metadata, regional_attributes)
- Required complex JOINs and frequent schema migrations
- ETL processing took 3–4 hours daily
- Schema updates caused downtime every 2–3 weeks
After the use of the Variant Data type resulted in Unified Architecture:
- Introduced Spark 4.0’s VARIANT data type in a single unified_content_metadata Delta table
- Stored flexible, semi-structured metadata in one column (metadata VARIANT)
- Eliminated the need for constant schema updates and reduced ETL time significantly
- Improved scalability, query performance, and simplified data management
Measurable Benefits
Metric | Before the use of the Variant Data type | After the use of the Variant Data type | Improvement observed |
Query Performance | 45-60 seconds | 8-12 seconds | 75% faster |
ETL Processing Time | 3-4 hours | 45 minutes | 80% reduction |
Schema Changes | 2-3 weeks | Same day | 95% faster deployment |
Storage Efficiency | 2.3 TB | 1.7 TB | 26% reduction |
Development Velocity | 2-3 weeks per feature | 3-5 days | 70% faster |
With this improvement, Netflix is about to launch new content categories and regional features, which is 3times faster, while reducing infrastructure costs by approximately $2.3 million annually.
Evolution in the Data Ecosystem
Spark SQL now includes powerful features like the VARIANT data type, SQL UDFs, session variables, pipe syntax, and string collation. These enhancements greatly improve SQL workload flexibility. This marks a shift toward better handling of semi-structured data.
Upcoming Innovations
- Advanced Analytics Integration: Future versions will support native ML functions on Variant data, reducing the need for manual feature engineering.
- Cross-Platform Standardization: Introducing VARIANT in Delta Lake aligns with other platforms, promoting broader ecosystem compatibility.
- Real-time Processing Enhancements: Spark 4.0 upgrades enable real-time analytics on Variant data streams using Structured Streaming.
Guidelines for Using Variant Data in Spark Workloads:
Best Practices | Common Pitfalls to Avoid |
Use Variant for genuinely semi-structured data with evolving schemas | Avoid storing simple key-value pairs that are better represented as regular columns |
Implement robust error handling for missing or optional fields | Do not assume all documents follow the same structure |
Monitor query performance and adjust partitioning strategies as needed | Avoid excessive nesting of data structures |
Use schema inference cautiously and cache results where applicable | Refrain from repeatedly parsing the same Variant fields without optimization |
Apply data validation during data ingestion | Do not ignore data quality issues under the assumption that Variant is flexible |
Summary:
The introduction of Variant data types in Spark 4.0 marks a pivotal shift in how semi-structured data is handled—merging flexibility with performance. By simplifying schema evolution, reducing ETL complexity, and enabling faster analytics, Variant empowers organizations to scale modern data workloads efficiently. With real-world impact seen in companies like Netflix, it’s clear that embracing this innovation can unlock significant operational and cost benefits across industries.