
And Why DAX Performance Depends on the Storage Engine A Complete Columnstore & Query Execution Story in Power BI
Power BI can analyze large datasets while maintaining interactive performance, mainly due to VertiPaq, its in-memory columnar storage engine.
Performance issues in Power BI are often misunderstood—some blame DAX, visuals, or Service limits.
In reality, performance depends on how data is stored (VertiPaq) and how queries run (DAX + engines).
This blog explains:
- How VertiPaq compresses data.
- How the Storage Engine and Formula Engine execute DAX.
- Why some DAX queries are fast, and others are slow.
- How to validate performance using VertiPaq Analyzer.
Problem Statement
In real Power BI projects, teams commonly face:
- Large PBIX file sizes.
- Slower reports as data grows.
- Long refresh times.
- Inconsistent visual performance.
- Simple DAX measures behave unpredictably.
These issues usually come from:
- Limited understanding of VertiPaq compression.
- High-cardinality columns.
- Poor schema design.
- DAX patterns that overuse the Formula Engine.
Without visibility into how data is stored and queried, optimization becomes guesswork.
VertiPaq Compression – Implementation with Practical Examples
Columnar Storage (Foundation of VertiPaq)
VertiPaq stores data column by column, not row by row.
Traditional Row Store:
Order ID | Date | Country | Sales |
101 | 2024-01-01 | IN | 100 |
VertiPaq Column Store:
| Order ID → [101,101,101…] | Date → [2024-01-01,…] | Country → [IN,…] | Sales → [100,…] |
Practical Impact
- Queries scan only required columns.
- Less memory access.
- Faster aggregations.
Row Store vs Column Store

Columnar storage scans only the necessary columns, reducing memory access and improving query speed.
Dictionary Encoding
VertiPaq replaces repeated values with integer keys using a dictionary.
Example – Country Column:
- Dictionary: 1 → IN, 2 → US, 3 → UK
- Encoded data: 1,1,1,2,3,1
Use Case
- Dimension attributes compress extremely well.
- Repeated text is stored only once.
Dictionary Encoding & Cardinality Comparison

Low-cardinality columns compress efficiently; high-cardinality columns increase dictionary size.
Value Encoding (Numeric Optimization)
VertiPaq chooses the smallest possible data type for numeric columns:
- Integers → minimal bits.
- Reduced decimal precision → better compression.
Use Case
- Avoid unnecessary decimal places.
- Prefer integers where possible.
Hash Encoding (High Cardinality Handling)
When a column contains highly unique values (e.g., transaction IDs, GUIDs, invoice numbers), VertiPaq cannot efficiently apply Value Encoding.
In such cases, it uses Hash Encoding, where values are mapped to hash keys stored in the dictionary.
Key Difference:
Value Encoding | Hash Encoding |
Used for numeric / low-cardinality columns | Used for high-cardinality columns |
Extremely memory efficient | Consumes more memory |
Stores values in minimal bits | Stores hashed references |
High-cardinality columns often trigger Hash Encoding and significantly increase model size.
Value vs Hash Encoding
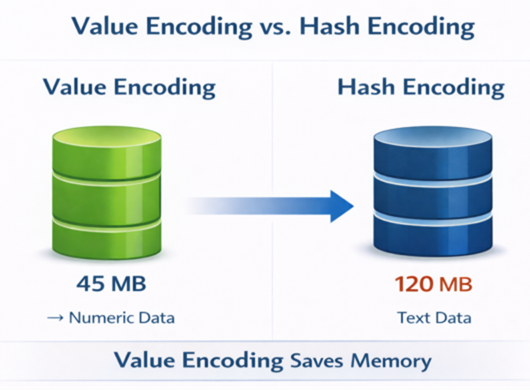
Value Encoding reduces memory consumption for numeric columns compared to Hash Encoding.
Run-Length Encoding (RLE)
Sequential repeated values are stored as counts.
Example:
1,1,1,1,2,2,3 → (1 × 4), (2 × 2), (3 × 1)
Works best for:
- Date columns.
- Sorted data.
- Dimension tables.
RLE Visualization
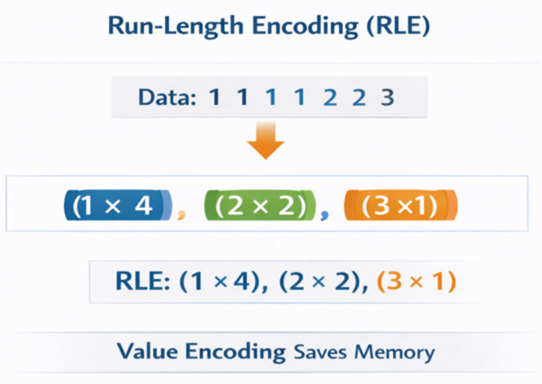
Run-Length Encoding (RLE) reduces memory for repeated values in sorted columns.
Segmentation
VertiPaq divides each column into segments of approximately 1 million rows.
Each segment is compressed independently.
Why Segmentation Exists
- Enables parallel query execution.
- Improves memory management.
- Supports incremental refresh.
- Reduces scan scope during filtering.
Example
If a table contains 5 million rows,
it will be divided into 5 segments.
When a report filters only recent dates,
only the relevant segment(s) are scanned.
Segmentation improves scalability and query efficiency at a large scale.
Columns are split into segments, each compressed independently.
Practical Benefit
- Only relevant segments are scanned during queries.
- Enables scalability and incremental refresh.
Segmentation Illustration
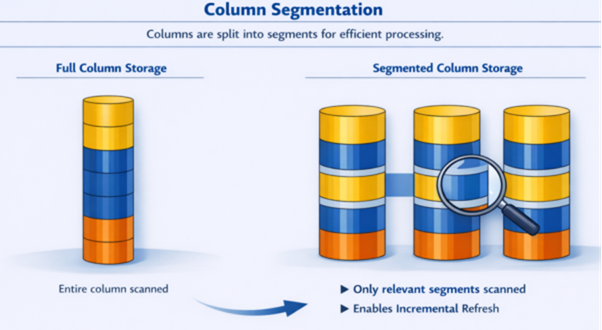
Segmentation allows queries to scan only necessary data, supporting incremental refresh.
DAX vs Storage Engine – Who Really Does the Work?
Engine Architecture Overview
Formula Engine (FE):
- Interprets DAX
- Handles iterators (SUMX, FILTER)
- Single-threaded
- Expensive for large datasets
Storage Engine (SE – VertiPaq):
- Executes scans & aggregations.
- Highly parallel.
- Works on compressed data.
- Extremely fast.
Golden Rule: Push as much work as possible to the Storage Engine.
Formula Engine vs Storage Engine
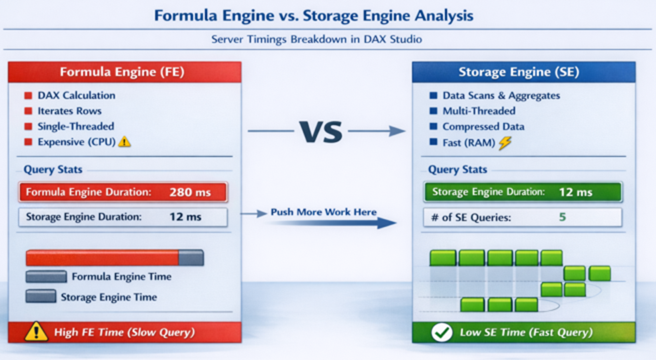
Efficient DAX pushes computation to the Storage Engine for faster query execution.
Practical DAX Examples
Storage Engine Friendly (FAST)
Total Sales := SUM(Sales[Amount])
- Entirely SE.
- Minimal FE involvement.
Formula Engine Heavy (SLOW)
Total Sales := SUMX(Sales, Sales[Quantity] * Sales[Price])
- Row-by-row evaluation
- Heavy FE workload
- Poor scalability
FILTER vs Direct Filters
Slower:
CALCULATE(SUM(Sales[Amount]), FILTER(Sales, Sales[Country]=”IN”))
Faster:
CALCULATE(SUM(Sales[Amount]), Sales[Country]=”IN”)
Direct filters allow the Storage Engine to process queries efficiently.
Key Features & Benefits
Performance
- Faster visuals.
- Reduced query execution time.
- Better concurrency in Power BI Service.
Memory Optimization
- Smaller PBIX size.
- Lower capacity usage.
- Better scalability.
Smarter Modeling
- Star schema validation.
- Avoid high cardinality traps.
- Reduced calculated columns.
Calculated Column vs Measure
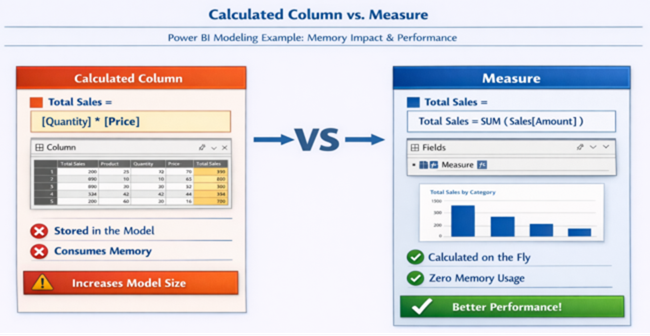
Measures do not consume VertiPaq memory, whereas calculated columns increase storage.
Validating Compression & Performance Using VertiPaq Analyzer
Understanding VertiPaq compression conceptually is important —
But validating it practically is critical.
What is VertiPaq Analyzer?
VertiPaq Analyzer is a diagnostic feature available through DAX Studio that allows you to inspect how your model is stored in memory.
It provides visibility into:
- Table size in memory
- Column size contribution
- Dictionary size
- Cardinality
- Encoding type (Value or Hash)
- Segment statistics
How to Use It
- Open your PBIX file
- Launch DAX Studio
- Connect to the data model
- Navigate to Advanced → View Metrics
- Export VertiPaq Analyzer results
What to Analyze
When reviewing metrics, focus on:
- Columns consuming disproportionate memory
- High-cardinality columns
- Large dictionary sizes
- Calculated columns increase storage
- Encoding type selection
Practical Example
If a text column consumes 35–40% of total model memory,
It likely has high cardinality and may require:
- Normalization into a dimension table
- Rounding or truncation
- Removal of unnecessary
Optimization should always be evidence-driven, not assumption-driven.
Conclusion
Power BI performance is not about choosing between DAX and VertiPaq. It’s about aligning both:
- VertiPaq determines how data is stored.
- DAX determines how efficiently data is queried.
Most performance problems occur when:
- High-cardinality data is poorly modelled.
- Formula Engine is overloaded unnecessarily.
- VertiPaq compression principles are ignored.
Takeaway: Fast Power BI reports are designed, not fixed. Understanding VertiPaq and DAX together is the foundation of scalable, enterprise-grade solutions.