
High-scale applications like Twitter, LinkedIn, and Gmail handle millions of users every day. Making sure everything runs smoothly is important, especially for simple tasks like checking if a username is available. But with so many users, even small tasks can slow down the system.
This is where Bloom Filters come in. They’re a smart, memory-efficient tool that helps systems answer questions quickly without checking every single record in the database.
In this blog, we’ll break down what Bloom Filters are, how they work, and why they’re so useful in building fast, high-scale applications. We’ll also include easy-to-understand visuals to make the concept clear.
Problem Statement:
Have you ever signed up for Twitter, LinkedIn, or Gmail and wondered how the system instantly tells you whether a username is available?
Here’s what’s happening behind the scenes:
- You type in a username, for example: Virat
- The system checks its database to see if Virat already exists
- If it does, you get a prompt: “Username taken, please try another one.”
Sounds simple, right? But here’s the twist — what if the platform has 20 million users or more?
- How do you efficiently check if a username is already taken without scanning all 20 million entries?
- What happens when hundreds of users are signing up at the same time and all try different usernames?
- Even if you add indexes to your database, can you really keep up with the scale?
Searching a massive database for every new signup becomes slow and resource-heavy. This is exactly the problem that Bloom Filters are designed to solve — quickly answering “Have I seen this before?” without putting a heavy load on your database.

Traditional Approach and Its Limitations
Before Bloom Filters, what would you normally do?
The most straightforward solution is to use a HashMap:
- Store all usernames in a HashMap
- Lookup is O(1) → super-fast, constant time
Sounds perfect, right? Well… not exactly.
The Catch: Memory Usage
Hash maps are great for speed, but terrible for memory when your dataset explodes.
- With millions of users, the hash map starts consuming huge amounts of space
- And remember — users keep signing up every day, so your memory requirements just keep growing
Imagine trying to store 20 million usernames in memory. Do you think your system can handle that easily?
Now Think About:
- What if your app grows from 20 million to 200 million users?
- Is speed still helpful if you’re running out of memory?
- Could you trade a little accuracy to save a lot of memory?
This is where Bloom Filters shine — giving you fast lookups without demanding huge chunks of memory.
The Solution: Bloom Filters to the Rescue
So, we know the problem: checking username availability at a massive scale is expensive. But what if I told you there’s a way to answer this question instantly, without scanning millions of records every time? Enter the Bloom Filter — a clever, space-efficient data structure designed to quickly test whether an element exists in a set. But how does it help?
Imagine this:
- You maintain a special “lookup map” of usernames.
- Whenever someone signs up, you check this map first.
- If the map says the username is taken, you don’t even hit the main database.
Sounds too good to be true? Well, there’s a catch: Bloom Filters are probabilistic. That means they can sometimes give a “maybe taken” answer even if the username isn’t actually taken — but they never say a taken username is free.

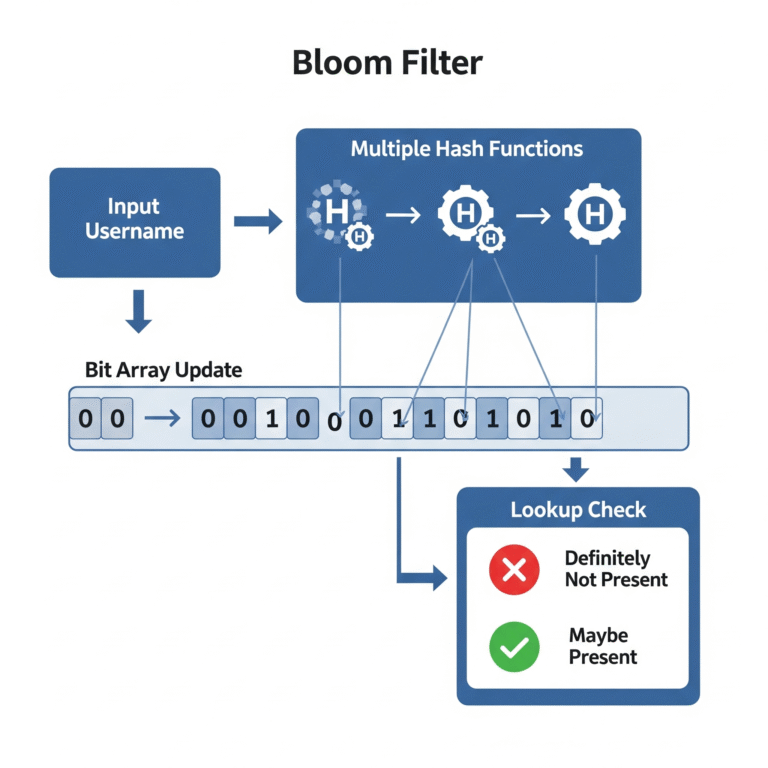
How Bloom Filters Work Behind the Scenes
Example: Office Security with Multiple Guards
Imagine an office where every visitor = a new username trying to sign up.
At the entrance, there are 3 guards = hash functions.
Step 1: When a new username is stored (Adding data)
- Suppose the username is “virat”.
- The system runs it through 3 different hash functions (like 3 guards checking different details).
- Each hash function gives a position in a big bit array (like a guard pointing to a spot in a notebook).
- Example:
- Guard 1 (hash 1) → position 2
- Guard 2 (hash 2) → position 7
- Guard 3 (hash 3) → position 15
- In the bit array, the system sets those positions to 1.
- Bit[2] = 1, Bit[7] = 1, Bit[15] = 1
Now, the system has marked that “virat” exists, without storing the full username in memory.
Step 2: When a new user checks availability (Lookup)
- Suppose a new person comes with the username “john”.
- The system again uses the same 3 hash functions.
- They give positions → [7, 15, 20].
- The database checks the bit array:
- Bit[7] = 1
- Bit[15] = 1
- Bit[20] = 0
- Since one bit is 0, the system knows for sure → “john” is not taken.
Just like the guards: if even one says “No”, the visitor (username) is not allowed.
Step 3: The False Positive Case
Now suppose someone tries “apple”:
- Hashes → [2, 7, 15]
- Database checks:
- Bit[2] = 1
- Bit[7] = 1
- Bit[15] = 1
All bits are 1, so the system says:
“This username might already exist.”
But actually, “apple” was never stored!
The overlap happened because “virat” also marked positions [2, 7, 15].
This is the false positive trade-off of Bloom Filters.
Why Databases Love This Trick
- Speed: Checking availability is just a few hash computations + bit lookups (very fast).
- Space efficiency: Instead of storing 20 million usernames in a hash map (huge memory), we just store a compact bit array.
- Trade-off: Sometimes it says a username exists when it actually doesn’t (false positive). But it will never say available if it’s already taken.
Real-World Applications of Bloom Filters
Bloom Filters aren’t just a cool theory — they’re used every day in the apps and platforms we rely on. Let’s look at some real-world places where they shine:
Instant Lookups (O(1))
- Twitter → Checks username availability instantly, even with hundreds of millions of users.
Space-Efficient Memory Usage
- LinkedIn → Quickly verifies if a profile ID already exists without keeping all IDs in memory.
High-Scale Friendly
- Gmail → Detects whether an incoming email looks like spam across billions of daily emails.
More Real-World Usage:
- Web Browsers (Chrome, Firefox) → Check if a website is malicious before loading.
- Email Systems (Gmail, Outlook) → Identify spam or duplicates efficiently.
- Databases (Cassandra, HBase, RocksDB, LevelDB) → Avoid unnecessary disk lookups by testing if a key might exist before searching storage.
- Spotify / YouTube → Confirm whether a song or video ID already exists in the catalog.
- CDNs (Content Delivery Networks) → Check if a file is in cache, speeding up delivery.
- E-commerce (Amazon, Flipkart) → Quickly check if a product ID has already been indexed in massive inventory systems.
Conclusion:
Bloom Filters are like a clever shortcut for massive systems.
They help us answer: “Have I seen this before?” super-fast, without needing to store every single detail.
Yes, there’s a small trade-off (sometimes they might say “already taken” even if it’s not). But the benefits far outweigh this tiny drawback when you’re dealing with millions of records.
Key Takeaways
- O(1) Lookups → Instant checks, no matter how big the dataset.
- Space-Efficient → Uses much less memory than storing everything in a hash map.
High-Scale Friendly → Perfect for systems with millions of entries.
- Real-World Usage → social media (Twitter, LinkedIn), email spam detection (Gmail), browser caching (Chrome/Firefox).