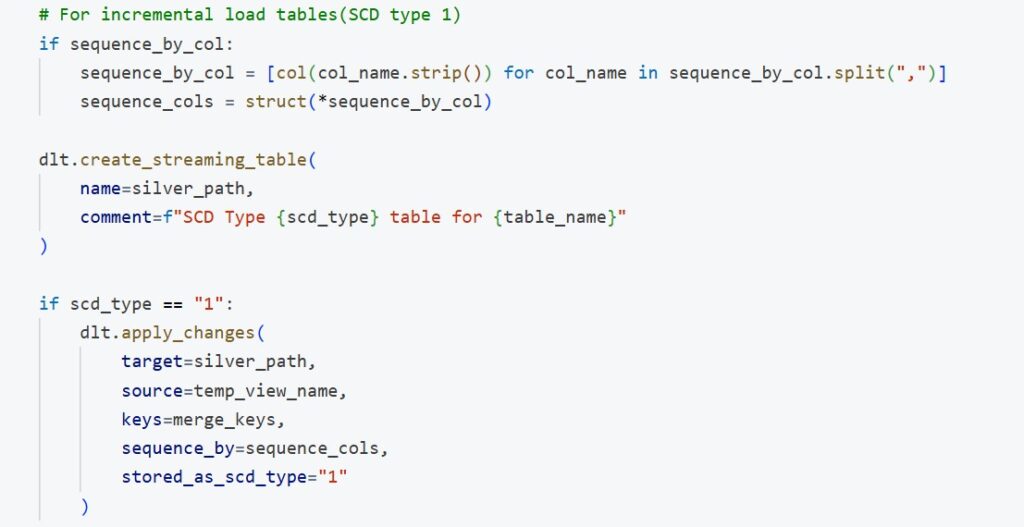
In the create_silver_table(config_rows, table) function:
config_rows contains all the configuration values for the given table.
Key values are extracted as follows:
catalog_name: The Unity Catalog catalog to register the Silver table.
database_name: The source database from which the data originates.
table_name: Name of the specific table being processed.
scd_type: Indicates which Slowly Changing Dimension (SCD) strategy (e.g., Type 1 or Type 2) to apply.
primary_key: A comma-separated list of primary key columns used for deduplication or merge logic.
merge_keys: A cleaned list derived from primary_key to use in merge operations.
sequence_by_col: The column used to order records for SCD logic (e.g., updated_at, dmsTimestamp).
bronze_path: The input path where the bronze table data is stored.
silver_path: The output path where the transformed silver table will be written.
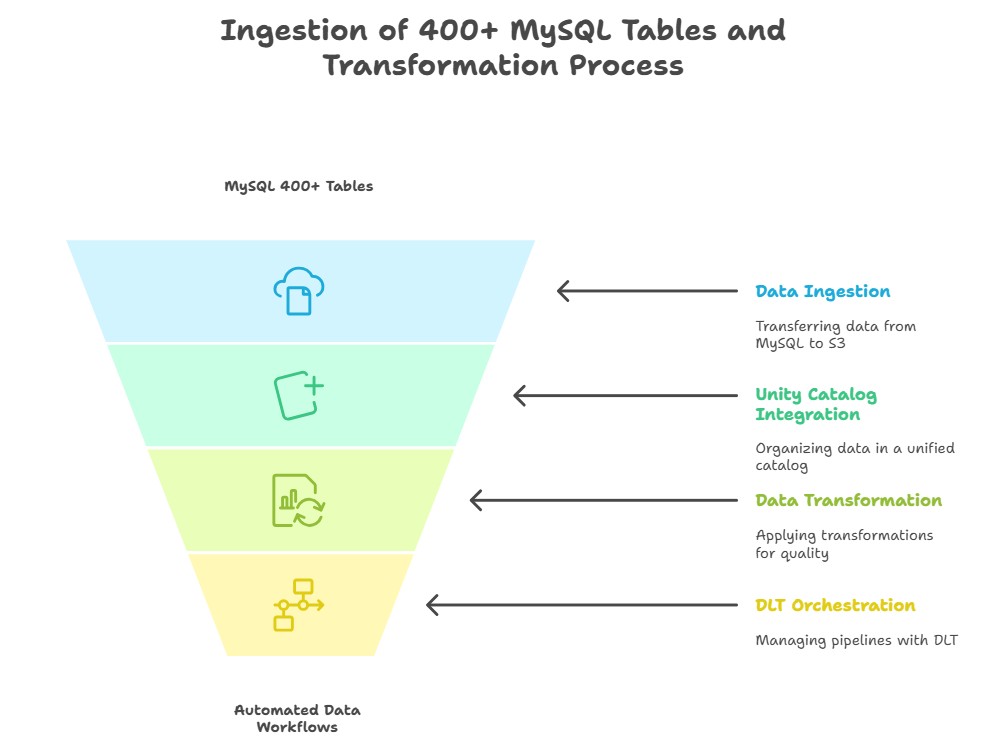
This structured configuration ensures that the silver layer transformation logic remains consistent, reusable, and easy to manage across hundreds of tables.
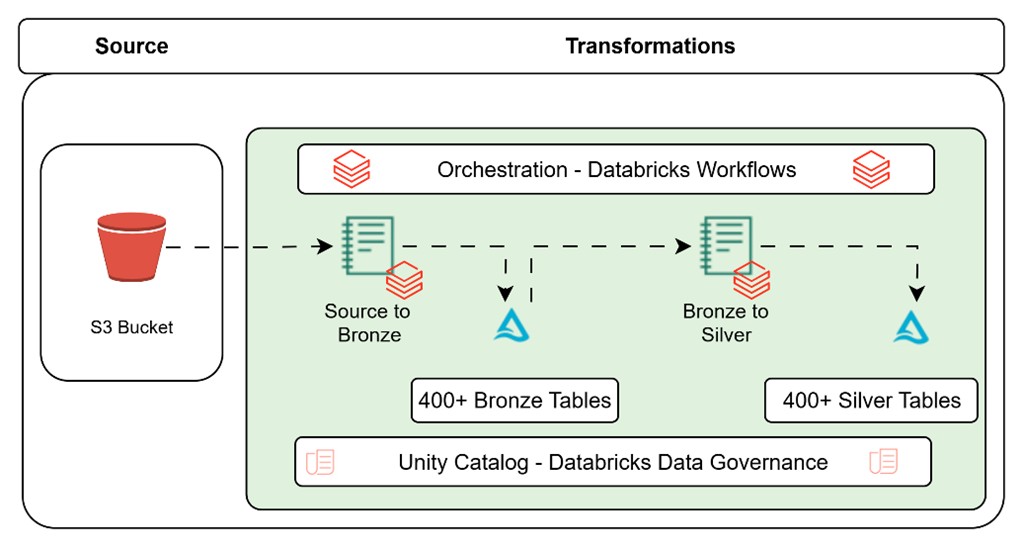
Scheduling & Orchestration:
We split workloads into two pipelines per frequency type:
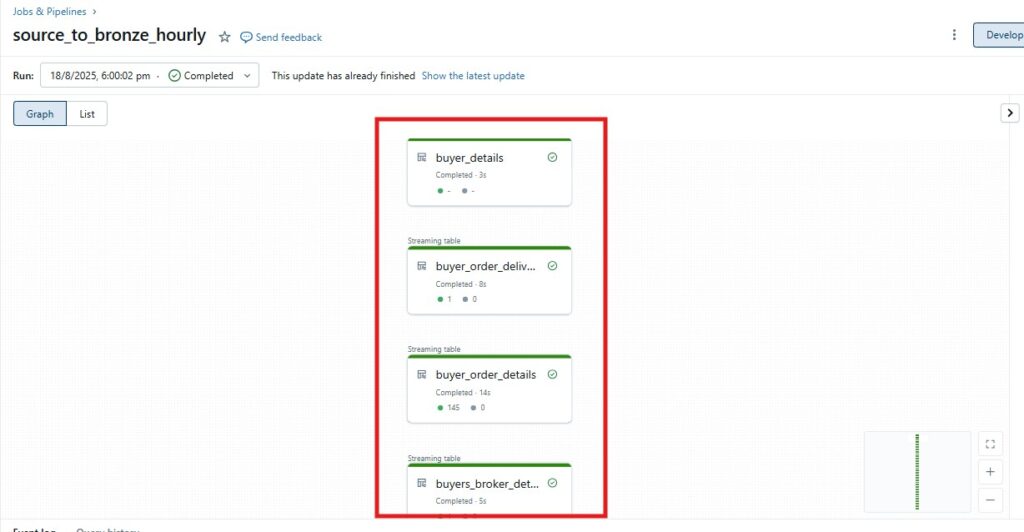
1. Source-to-Bronze – Reads from S3 and lands data in bronze tables.
Dynamic Table Selection – Pipeline reads table_config and filters tables at runtime using frequency_type (hourly, daily, weekly, etc.) for targeted ingestion.