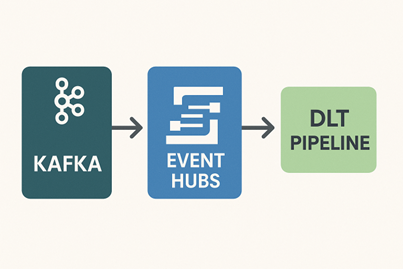
Kafka (Producer):
Kafka is a distributed streaming platform that lets you publish and subscribe to streams of records. It acts as a highly scalable and fault-tolerant messaging system. In this blog, we used the confluent_kafka Python library to simulate a Kafka producer that sends data to Azure Event Hub.
Internal Working of Kafka Producer:
When you call producer , Kafka’s client library buffers the message in memory. It batches multiple messages to improve throughput before sending them to the broker. The flush() method forces any remaining messages to be sent immediately. Kafka’s replication ensures that once a broker acknowledges the message, it is safely written to disk and replicated to other brokers, protecting against data loss.
Azure Event Hub (Streaming Broker):
Event Hub is a fully managed, real-time data ingestion service from Azure that can receive and process millions of events per second. It works similarly to Kafka topics. It’s ideal for streaming scenarios and integrates well with Azure and Databricks.
- Retention period: Default is 1 day, can be extended up to 90 days.
- Use case: Acts as the intermediate buffer to store Kafka messages temporarily.
System Internals of Azure Event Hub:
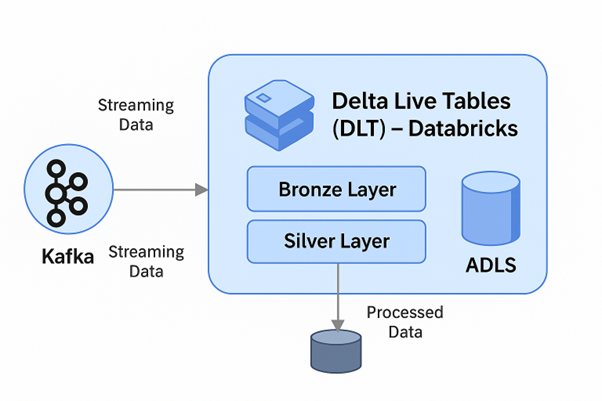
Event Hub stores incoming messages in partitions for parallel processing. Internally, it uses a distributed commit log like Kafka. Each partition has its own sequence of offsets, which consumers track to ensure exactly-once or at-least-once processing. Event Hub replicates data within the Azure region for high durability. The Capture feature writes raw streaming data automatically to Azure Storage or ADLS, which provides long-term retention beyond the Event Hub retention window.
Delta Live Tables (DLT) – Databricks (Consumer):
DLT is a framework for building reliable, automated, and production-ready streaming pipelines. It simplifies ingestion, transformation, and orchestration of data workflows.
- Bronze Layer: Ingests raw streaming data from Event Hub.
- Silver Layer: Transforms and deduplicates/updates the data.
Internal Working of Delta Live Tables (DLT):
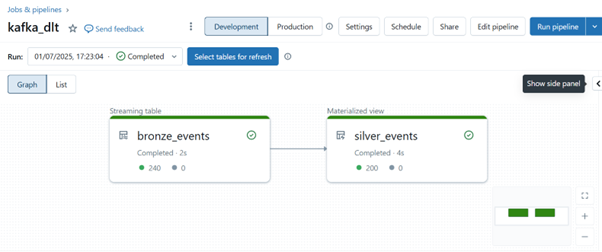
DLT runs on top of Apache Spark Structured Streaming. It continuously reads data in micro-batches, tracking the streaming state using checkpoints stored in a Delta log. For deduplication and updates, DLT manages metadata about previously seen records. Transactions are atomic, meaning partially written batches won’t corrupt downstream tables. If the pipeline fails, DLT can recover exactly where it left off using the checkpoint and transaction log.
Architecture: