
If you’re working with PySpark, you’ve probably asked yourself this at some point:
“Should I use a built-in function or just write my own?”
Great question — and one that can have a huge impact on your Spark application’s performance.
In PySpark, there are two main ways to transform or manipulate your data:
- Using Inbuilt Functions
- Writing User-Defined Functions (UDFs)
They both can get the job done, but they work very differently under the hood — and one is almost always better than the other.
Let’s break it down. No fluff. Just code, examples, and real-world advice.
What Are Inbuilt Functions?
Inbuilt (or built-in) functions are functions provided directly by the pyspark.sql.functions module. These are optimized by Spark itself and are written in Scala/Java for the JVM.
These functions include:
- String functions: upper(), lower(), concat(), substr(), trim(), etc.
- Date/time functions: current_date(), datediff(), date_add(), year(), month(), etc.
- Math functions: abs(), round(), sqrt(), log(), etc.
- Conditional functions: when(), otherwise(), coalesce(), etc.
- Collection functions: explode(), array_contains(), etc.
Why Use Inbuilt Functions?
Inbuilt functions are:
- Super fast
- Natively optimized by Spark’s Catalyst Optimizer
- Executed inside the JVM, avoiding expensive data movement
- Automatically parallelized across worker nodes
This makes them ideal for large-scale, distributed data processing.
Example: Using upper() to convert names to uppercase
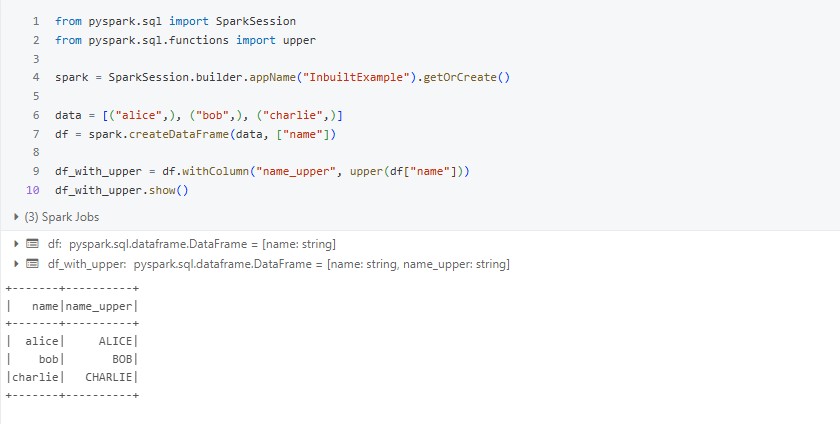
What is a UDF (User-Defined Function)?
A UDF is a way to write your own function in Python, Scala, or Java and apply it to Spark DataFrames.
You use a UDF when:
- There’s no inbuilt function that does what you need.
- You need to apply complex business logic or transformation rules.
- You’re using external libraries (e.g., NLP, regex, or third-party tools).
Why UDFs Are Slower
Spark runs on the JVM (Java Virtual Machine), but Python UDFs are executed outside of the JVM in the Python process (using Py4J). This causes a data serialization bottleneck:
- Spark serializes data from the JVM to Python.
- Python executes your UDF.
- Results are serialized back to the JVM.
This serialization/deserialization slows things down a lot, especially with big data.
Example: UDF that mimics upper()
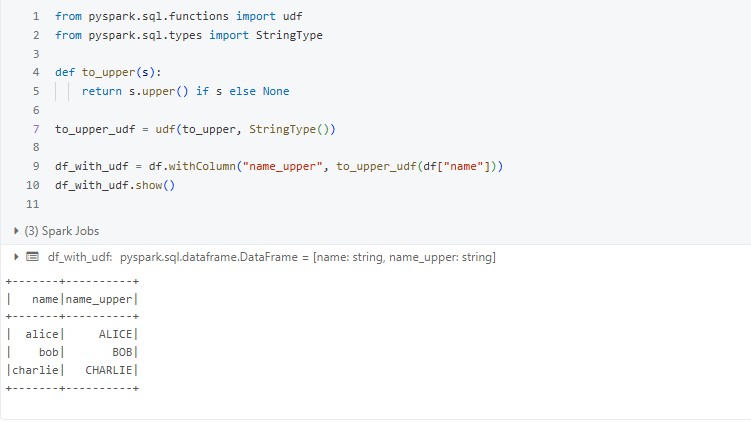
Looks the same, but it’s much slower. Why use it if upper() already exists?
Quick Speed Test — UDF vs Inbuilt Function
Let’s benchmark the two on a larger DataFrame:
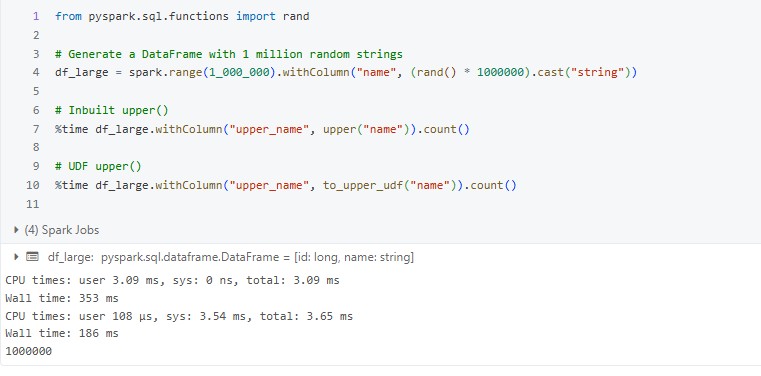
Typical Results:
- Inbuilt function: ~2–4 seconds
- UDF: ~15–25 seconds (or more)
The bigger your dataset, the worse the UDF performs.
When Should You Use UDFs?
UDFs should be used only when necessary. For example:
- You need logic that Spark doesn’t support.
- You’re calling an external Python library (e.g., nltk, sklearn, re).
- You must implement a business rule not expressible in SQL or DataFrame APIs.
Example: Custom sentiment classifier (NLP UDF)

This logic can’t be done using inbuilt functions — so a UDF makes sense here
Always Try Inbuilt Functions First
They’re:
- Fast
- Clean
- Catalyst-optimized
- Designed for distributed computing
Use UDFs Sparingly
Reach for a UDF only when:
- There’s no equivalent built in
- You have specialized logic or external library requirements
Test for Performance
Use .explain() to see Spark’s execution plan and .count() or .timeit to measure performance.
Wrapping Up
Choosing the right function type in PySpark isn’t just about syntax — it’s about performance, scalability, and getting the most out of Spark’s distributed engine.
Inbuilt functions = Fast, native, reliable
Python UDFs = Slower, costly
Always ask: Can I do this with an inbuilt function?
If yes, you’re on the right path. If no — UDF carefully.