
Essence:
As businesses grow and handle ever-larger datasets, the demand for efficient data synchronization and management tools becomes increasingly essential.
“Salesforce offers a robust ecosystem with a variety of APIs that facilitate seamless integration with external systems and enhance overall process efficiency.”
It has become essential for the firm to deal with larger data sets more efficiently.
This article delves into Salesforce APIs and demonstrates how their implementation delivers effective and scalable integration solutions, particularly the Bulk API.
Salesforce API’s:
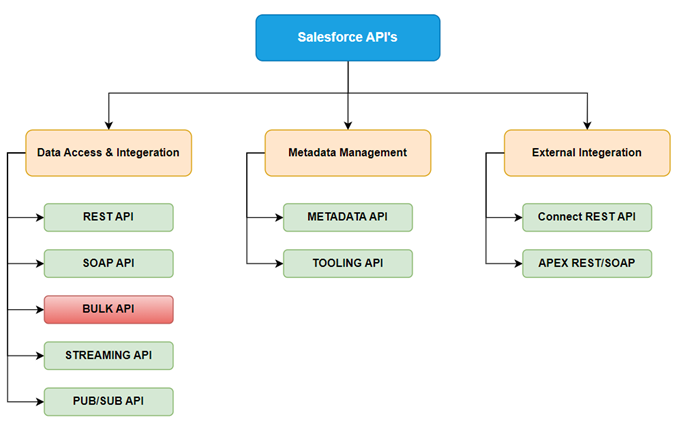
Data Access & Integration APIs
Used to read, write, update, and delete Salesforce data.
REST API
- Best for: Lightweight integrations, mobile apps, web clients.
- Protocol: HTTP methods (GET, POST, PATCH, DELETE).
- Format: JSON (mainly) or XML.
- Use Case: CRUD operations on Salesforce objects.
SOAP API
- Best for: Enterprise systems or legacy applications.
- Protocol: XML-based web service.
- Format: WSDL, XML.
- Use Case: CRUD operations with strong typing and enterprise security.
Bulk API
- Best for: Large volume data loads (millions of records).
- Version: Bulk API v1.0 (CSV-based), v2.0 (more scalable).
- Use Case: Batch processing (insert, update, delete, upsert) asynchronously.
Streaming API
- Best for: Real-time event notification using PushTopic or Generic Events.
- Protocol: Bayeux over CometD (long polling).
- Use Case: Get notified when records change without polling.
Pub/Sub API
- Best for: Scalable event-driven architecture using gRPC + Protobuf.
- Use Case: Publish/subscribe to platform events and change data capture (CDC).
Metadata Management APIs
Used for managing and deploying Salesforce configuration and metadata.
Metadata API
- Best for: Deploying customizations (fields, layouts, Apex classes) between orgs.
- Use Case: CI/CD, Salesforce DX deployments, org-to-org migration.
Tooling API
- Best for: Building custom developer tools (like IDEs).
- Use Case: Access object metadata, Apex classes, triggers, and debug logs programmatically.
External Integration APIs
Used to connect Salesforce with external systems.
Connect REST API
- Best for: Accessing External Objects via Salesforce Connect.
- Use Case: View and search external data (e.g., from SAP, Oracle) in Salesforce without copying it.
Apex REST / Apex SOAP
- Best for: Custom API development inside Salesforce using Apex code.
- Use Case: Expose custom business logic via REST/SOAP endpoints.
Understanding Bulk API and Asynchronous Requests:
The Bulk API in Salesforce is built on REST principles and is specifically optimized for handling large volumes of data. It’s ideal for operations like inserting, updating, upserting, or deleting thousands—or even millions—of records. Unlike traditional APIs, it works asynchronously, meaning you submit a request and check back later for the results, allowing Salesforce to process everything in the background efficiently.
On the other hand, REST APIs are designed for real-time interactions and work best when you’re updating just a few records at a time. While they can handle larger datasets, they’re not well-suited for heavy loads. When dealing with hundreds of thousands of records, the Bulk API is a far more practical and scalable choice.
Deep diving into the process:
Let’s dive deep into the process.
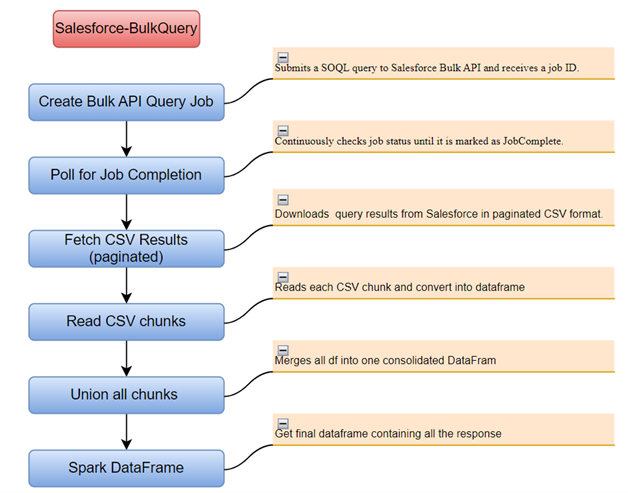
Understanding the process:
Create Bulk API Query Job:
A SOQL query is submitted to Salesforce via the Bulk API.
This is done by making a POST request

Salesforce accepts the job, begins processing it asynchronously, and returns a unique job ID like 743629rhairgsjkwiw12(sample). This job ID is used in the next steps to track the progress and fetch results.
Sample response:
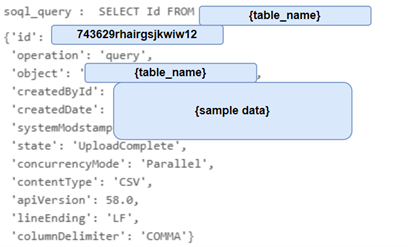
Response Parameters:
Parameter | Type | Description |
id | string | The unique ID for this job. |
operation | OperationEnum | The type of query. Possible values are: |
query—Returns data that hasn’t been deleted or archived. QueryAll—Returns records that have been deleted because of a merge or delete, and returns information about archived Task and Event records | ||
object | string | The object type being queried. |
createdById | string | The ID of the user who created the job. |
createdDate | dateTime | The UTC date and time when the job was created. |
systemModstamp | dateTime | The UTC date and time when the API last updated the job information. |
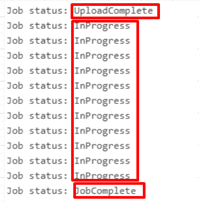
state | JobStateEnum | The current state of processing for the job. Possible values are: UploadComplete—The job is ready to be processed, and Salesforce has put the job in the queue. InProgress—Salesforce is processing the job. Aborted—The job has been aborted. See Abort a Query Job. JobComplete—Salesforce has finished processing the job. Failed—The job failed. |
concurrencyMode | ConcurrencyModeEnum | Reserved for future use. How the request is processed. Currently, only the parallel mode is supported. (When other modes are added, the API chooses the mode automatically. The mode isn’t user configurable.) |
contentType | ContentType | The format that is used for the results. Currently, the only supported value is CSV. |
apiVersion | string | The API version that the job was created in. |
jobType | JobTypeEnum | The job’s type. For a query job, the type is always V2Query. |
lineEnding | LineEndingEnum | The line ending used for CSV job data marks the end of a data row. The default is LF. Possible values are: |
LF—linefeed character | ||
CRLF—carriage return character followed by a linefeed character | ||
columnDelimiter | ColumnDelimiterEnum | The column delimiter used for CSV job data. The default value is COMMA. Possible values are: BACKQUOTE—back quote character (`) CARET—caret character (^) COMMA—comma character (,) PIPE—pipe character (|) SEMICOLON—semicolon character (;) TAB—tab character |
numberRecordsProcessed | long | The number of records processed in this job. |
retries | int | The number of times that Salesforce attempted to save the results of an operation. Repeated attempts indicate a problem, such as a lock contention. |
totalProcessingTime | long | The number of milliseconds taken to process the job. |
isPkChunkingSupported | boolean | Whether PK chunking is supported for the queried object (true), or isn’t supported (false). |
Poll for Job Completion:
Since the job runs in the background, we need to continuously poll its status until it’s complete. This is done using the job status endpoint:

We keep polling until the job state is JobComplete. If the state is Failed or Aborted, we log or raise an error. If it takes too long, we time out gracefully.
Fetch CSV Results (Paginated):
Once the job is complete, Salesforce exposes the results via a paginated CSV endpoint:

The results are returned as plain text CSV data. If the result is large, Salesforce splits it into pages using the Sforce-Locator header, and we must loop over these pages to fetch all the data.

Read CSV Chunks:
Each page of the CSV result is streamed using the requests library.
- Use StringIO to wrap the CSV text like a file.
- Use read_csv() to parse it (optionally with chunksize for large volumes).
- Convert each Pandas DataFrame chunk into a PySpark DataFrame.
If we read the data in chunks (via pagination and/or Pandas chunking), we will union all the Spark DataFrames together.
Final Spark DataFrame:
After we will get one complete dataframe which contains all the responses.
Use Cases for Salesforce Bulk API 2.0:
Salesforce Bulk API 2.0 is purpose-built for handling massive volumes of data with efficiency, making it a core tool for architects and developers managing large-scale Salesforce environments. Below are the most impactful and real-world use cases:
1️. Data Migration from Legacy Systems
When moving from older CRM or ERP systems to Salesforce, Bulk API 2.0 enables you to ingest millions of records efficiently. Its high throughput and async processing make it ideal for one-time or phased migration strategies.
2️. Cross-System Data Integration
For integrating data from external platforms (like SAP, Oracle, Marketo, Snowflake, or custom databases), Bulk API 2.0 supports efficient, large-scale ingestion without impacting Salesforce performance. This is crucial for real-time and near-real-time sync scenarios.
3️. Nightly or Scheduled Batch Jobs
Routine background tasks like data deduplication, enrichment, archival, and cleansing are a perfect fit. You can schedule Bulk API jobs to clean or update massive datasets overnight without hitting synchronous limits.
4️. Analytics and Reporting Pipelines
Feeding large datasets into Salesforce for reporting dashboards or exporting Salesforce data to downstream BI tools (like Tableau, Power BI, or Snowflake) can be done quickly and reliably using Bulk API’s asynchronous capabilities.
5️. Marketing Data Loads
Bulk imports of leads, campaign data, engagement metrics, and segmentation lists from marketing platforms can be handled efficiently. This supports better campaign automation, segmentation, and analytics.
6️. IoT and Event Data Ingestion
Companies collecting real-time sensor or IoT data (e.g., device logs, usage metrics) can batch those records and push them periodically into Salesforce using Bulk API for tracking and action triggers.
7️. Archival and Compliance Updates
When complying with legal or business policies (like GDPR, data retention, etc.), you might need to mass update, delete, or export customer records. Bulk API simplifies this without overloading the system.
8️. Transactional Record Processing at Scale
Systems like e-commerce platforms, finance tools, or logistics apps that generate high-frequency transactions can accumulate thousands of records daily. Bulk API 2.0 enables efficient upsert of this data to Salesforce, supporting accurate forecasting and order tracking.
Flow visualization:

The Evolution of Salesforce Bulk API 2.0: A Necessary Step Forward
While Salesforce Bulk API 2.0 has revolutionized the way we handle large-scale data operations in the Salesforce ecosystem, it’s not without its limitations. As organizations increasingly demand faster, more flexible, and more reliable data processing, Salesforce continues to refine its platform to meet these needs.
Despite the impressive capabilities of Bulk API 2.0—especially in managing millions of records asynchronously—certain gaps still exist when it comes to performance optimization, real-time responsiveness, and resource efficiency.
To address these challenges, Salesforce is evolving once again.
What’s Next?
- Introducing Events &
- Partial Downloads in Bulk API 2.0
As part of its ongoing improvements, Salesforce is rolling out two major enhancements to the Bulk API 2.0 framework:
1️. Event-Driven Architecture
Salesforce is moving toward a more event-based processing model for Bulk API operations. This change aims to reduce polling overhead and provide near-real-time notifications when a job completes, fails, or reaches specific checkpoints. This shift will:
- Improve system responsiveness
- Eliminate unnecessary API calls
- Help automate workflows around data ingestion pipelines
2️. Partial Downloads for Query Jobs
Handling very large result sets has always been a pain point. With Partial Downloads, you no longer have to wait for the full result set to be available before starting your data processing. This enhancement allows:
- Streaming of data as it becomes available
- Faster time-to-first-record
- More efficient memory usage and processing for large-scale ETL jobs
Why It Matters:
These improvements are not just technical upgrades—they’re strategic enhancements aimed at scaling enterprise data operations. By introducing event-driven triggers and streamable partial responses, Salesforce is pushing Bulk API 2.0 toward becoming a true modern data ingestion framework that aligns with cloud-native, real-time architecture.
Conclusion
Salesforce Bulk API 2.0 is not just a performance upgrade — it’s a strategic tool for data-intensive operations. Its ability to handle millions of records, robust error handling, and asynchronous execution model make it the backbone of modern, scalable Salesforce data engineering. Whether you’re running migrations, feeding marketing systems, syncing external CRMs, or processing high-volume.