Triggering Azure Data Factory (ADF) Pipelines from Databricks Notebooks
Overview
In modern data workflows, it’s common to combine the orchestration capabilities of Azure Data Factory (ADF) with the powerful data processing of Databricks. This blog demonstrates how to trigger an ADF pipeline directly from a Databricks notebook using REST API and Python.
We’ll cover:
Required configurations and widgets
Azure AD authentication
Pipeline trigger logic
Polling ADF status until completion
Required Libraries
Start by importing the necessary libraries:
Notebook Parameters
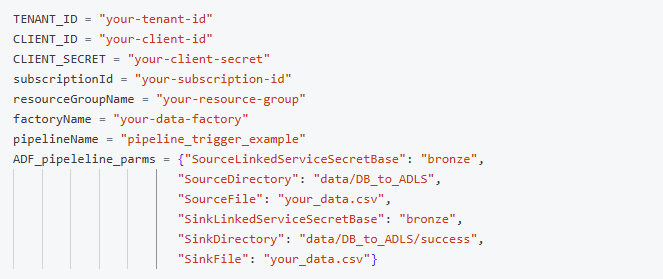
We use dbutils.widgets to pass the required Azure credentials and pipeline details dynamically.
Retrieve the widget values and construct the ADF pipeline URL:
Example Input (Widget Parameters):
Note: The parameter keys and values used in this example are based on sample Databricks and ADF pipeline configurations. Please feel free to modify or adapt them according to the specific parameters required by your Databricks environment and Azure Data Factory pipeline setup.
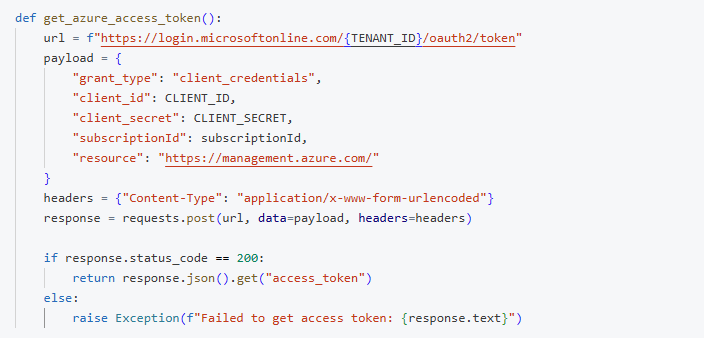
Azure Authentication Logic
Get an Azure access token using client credentials:
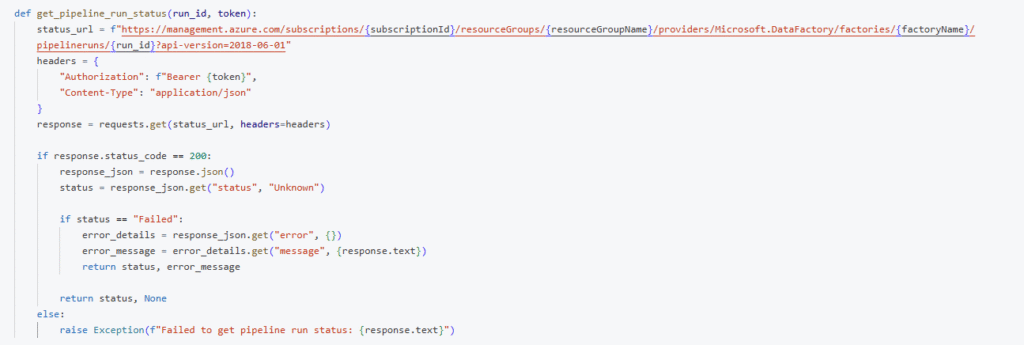
Polling ADF Pipeline Status
Trigger the ADF Pipeline
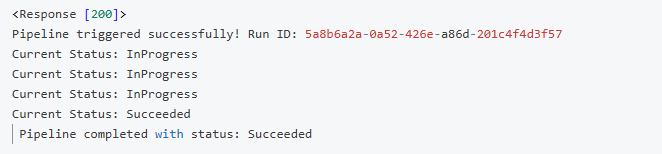
This function triggers the ADF pipeline and monitors it until completion.
Execution
Finally, run the function with appropriate parameters:
Sample Output Logs:
Advantages
Unified Orchestration: Trigger and monitor ADF directly from Databricks notebooks, improving control and visibility.
Parameterization: Pass pipeline parameters dynamically at runtime.
Authentication Security: Uses Azure AD tokens via service principal (client credentials).
Monitoring: Built-in polling to monitor pipeline success/failure.
Scalable: Easily extendable for multiple pipelines or error handling strategies.
Disadvantages
Manual Token Expiry Handling: Azure AD access tokens expire after a certain time (typically 1 hour). If the token expires mid-execution, the pipeline trigger or status polling may fail unless the logic is extended to refresh tokens.
Hardcoding Risk in Widgets: Although widgets make it easier to pass parameters, managing secrets like CLIENT_SECRET directly through widgets (instead of a secret scope or key vault) may raise security concerns.
Limited Error Transparency: The error response from ADF may not always provide complete context, making debugging failed pipelines a bit challenging unless detailed logging is added.
Latency in Status Polling: Polling the pipeline status every few seconds introduces latency. For long-running pipelines, this might unnecessarily consume compute resources on Databricks.
Tight Coupling of Platforms: Tying ADF execution tightly to Databricks increases interdependency. Any downtime or failure in Databricks can potentially delay or block critical ADF workflows.
Limited Retry Logic: This implementation lacks built-in retries. If ADF fails due to transient issues (like network hiccups or resource constraints), it won’t automatically attempt a retry unless you add such logic
Additional Enhancements (Future Scope)
Add Azure Key Vault integration to securely retrieve secrets.
Modularize the logic for reuse in production pipelines.
Enable logging and alerts to Azure Monitor or Teams.
Add support for retry logic and timeout handling.
Conclusion
Triggering ADF pipelines from Databricks provides powerful flexibility in managing data workflows. With REST API-based integration, you can dynamically orchestrate downstream data movement and transformation tasks directly from your notebooks.