Unleashing the Power of Explode in PySpark: A Comprehensive Guide
Efficiently transforming nested data into individual rows form helps ensure accurate processing and analysis in PySpark. This guide shows you how to harness explode to streamline your data preparation process.
Modern data pipelines increasingly deal with nested, semi-structured data — like JSON arrays, structs, or lists of values inside a single column. This is especially common when ingesting data from APIs, NoSQL databases, and Event streams (IoT, logs).
As data engineers and analysts, we frequently confront issues in flattening nested data for easier querying and analysis. The explode function in PySpark is a useful tool in these situations, allowing us to normalize intricate structures into tabular form. The workflow may be greatly streamlined by knowing when and how to employ explode, whether you are cleaning data, getting it ready for machine learning, or creating dashboards.
To help you apply explode with confidence in real-world PySpark applications, we’ll take you through this blog related to the performance suggestions, use cases, and real-world examples in this article.
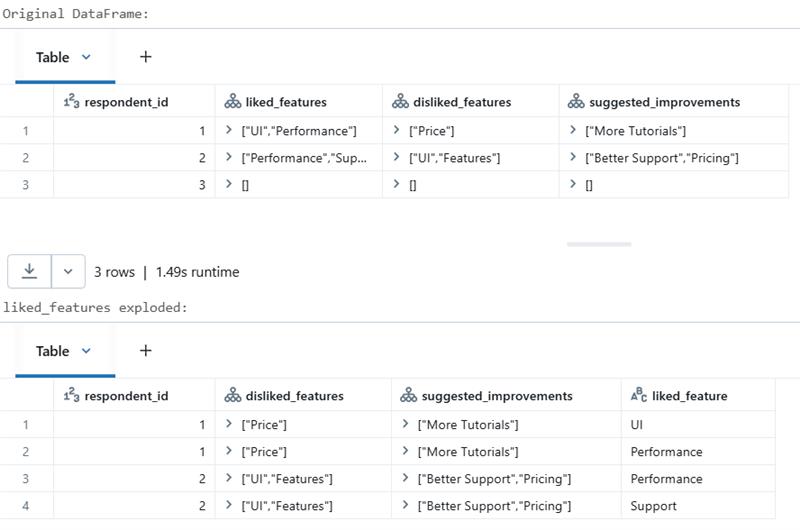
Consider the JSON data below, which holds information related to a customer feedback survey.Each respondent can select multiple answers for the different features available below:
liked_features: Which features did you like?
disliked_features: Which features did you dislike?
suggested_improvements: What would you like to see improved?
In these cases, you often need to flatten the nested data structures into a tabular format to make them usable for Analytics and reporting. One of the methods to flatten or unnest the data is the explode () function in PySpark.
Flatten here refers to transforming nested data structures into a simple row-and-column (tabular) format.
File by flatten in PySpark refers to flattening your nested data and then storing it as a file with the desired format for downstream use.
Current Challenges faced when dealing with JSON data:
Pipelines produce inaccurate aggregates (overcounts, duplicates).
Data quality suffers, driving wrong business decisions.
Storage costs rise due to unnecessary data bloat.
Query performance degrades due to excessive shuffling or unnecessary joins.
Debugging root causes becomes time-consuming.
What is the explode() function in PySpark?
Columns containing Array or Map data types may be present, for instance, when you read data from a source and load it into a DataFrame. Explode makes it easier to transform the nested data into a tabular format, where each element is displayed as a separate row.
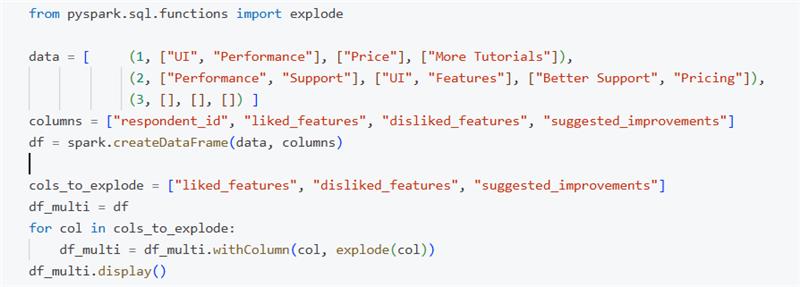
Let us take the above JSON example mentioned and use the explode() function on the same and see how the data is being flattened.
Explode a single column: Depending on a feature (column) selection, you can explode a single column to view the features.
Output:
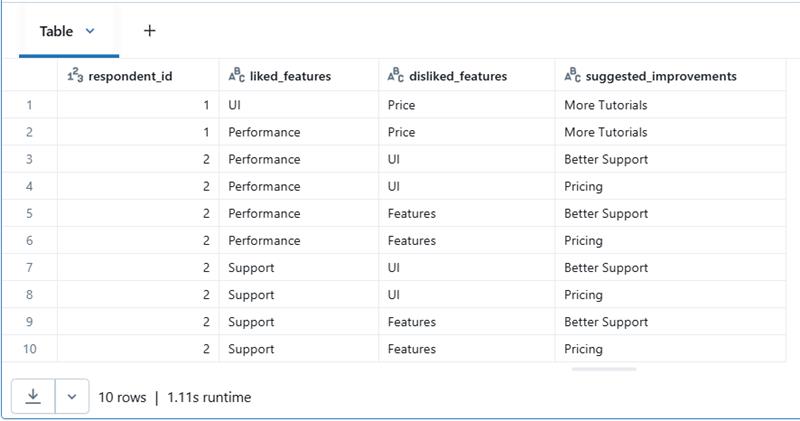
Explode all the array / Map type columns: You must also explode all the other columns if you wish to analyse every feature.
Output:
Why do we need explode?
Nestled data, such as JSON, XML, arrays, or maps in semi-structured data, is quite frequent in real-world large data. As a result, when we use explode, we have a single row with several values in a single column, easier to analyse.
Moreover, arrays are difficult to work with for analytical operations like group by, join, filter, or count.
BI tools, CSV exports, and SQL queries are examples of downstream tools that require flat, tabular data rather than arrays or maps.
Thus, explode makes,
Easier aggregation.
Easier to join dimension tables.
Easier to filter on individual elements.
Let us now get into other types of explode functions in PySpark, which help us to flatten the nested columns in the dataframe.
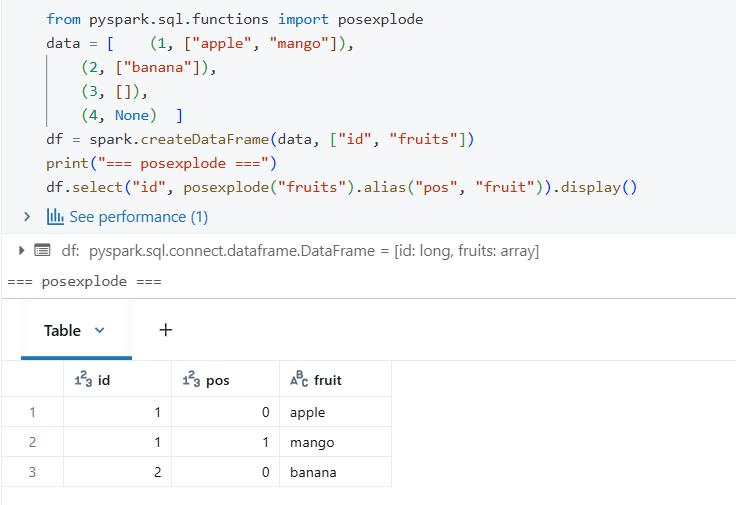
posexplode() function like explode() function, but also gives you the position (index) of each element.
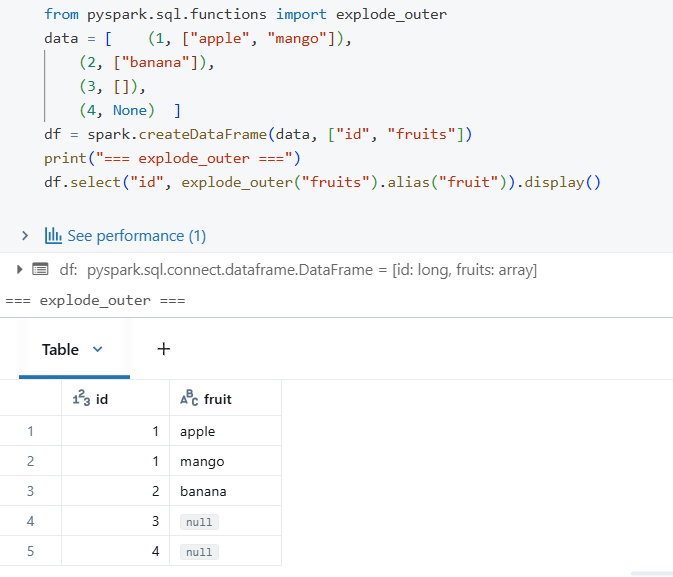
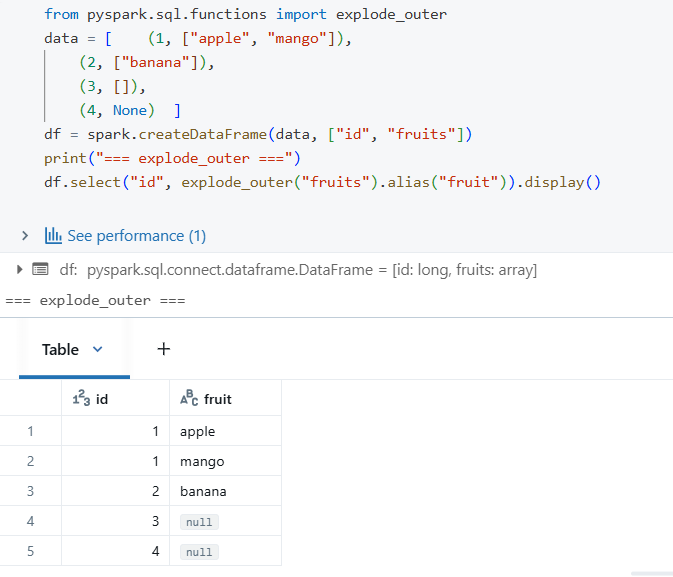
The explode_outer() function is the same as explode, but if the array is null or empty, it keeps the row with null values.
posexplode_outer() function combines the result set of posexplode() with explode_outer() function.
To sum up all the types of explode functions and knowing their ability to drop/retain the null rows in a dataframe in PySpark is mentioned below:
Function
Best for
Null rows
explode
Used to flatten arrays or maps in a DataFrame.
Drops rows that contain null arrays in the DataFrame.
posexplode
Ideal for flattening while maintaining the position of each nested element.
Drops rows with null arrays in the DataFrame.
explode_outer
Useful for flattening while also retaining rows with null arrays.
Keeps rows that have null arrays in the DataFrame.
posexplode_outer
Helps flatten nested data, preserve element positions, and retain null rows.
Keeps rows with null arrays in the DataFrame.
Behaviour Detail: When you use the xplode() or posexplode() function, the related rows will only be removed from the result set if the entire array is null or empty.
Suppose we have an array that contains a null value, for example, [“apple”, “mango”,””]. In this instance, using posexplode() or explode() will not cause the row to be dropped. The position of the null value will be stated, or the related value will be null, respectively.